
统计学习方法(1)统计学习方法概论

人间有味是清欢
0. 前言
- 感想
- 知乎这markdown公式输入……不想再来一次了……得想想办法解决……
- 半路出家算法工程师的辛酸学习历程,水平有限(特别是数学),仅供参考……
- 还是没完全搞清最大后验概率估计和贝叶斯估计的区别,晕乎乎的……
- 我能把整本书的笔记都写完吗?
- 参考资料
- 各种资料,查过的太多了……
- 贝叶斯估计、最大似然估计、最大后验概率估计 推荐
- 统计学习方法:习题笔记 推荐
- 《统计学习方法》第1章 课后题答案
- 李航 统计学习方法 第一章 课后 习题 答案
- 深度之眼课程。
- 学习要求(供参考):
- 理解《本章概要》(即《统计学习方法》每一章末尾的总结)的5点内容。
- 理解模型过拟合产生的原因和造成的影响。
- 理解机器学习的评价标准,模型的泛化能力。
- 熟悉极大似然估计和贝叶斯估计的基本思想和求解方法。
- 主要内容:
- 书本内容梳理
- 疑难点
- 课程习题
- 书本习题
1. 书本内容梳理
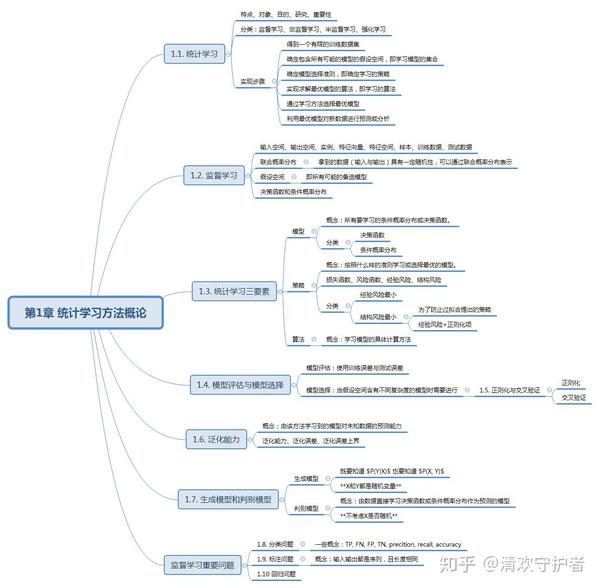
1.1. 思维导图

1.2. 数学相关
- 最大似然估计与贝叶斯估计
2. 疑难点
2.1. 输入空间与特征空间
- 一般情况下,两者等价。
- 特殊情况下,如输入空间为 x,特征空间可能为 x, x^2, x^3 ,则两者不等价。
- 例如SVM中使用核函数。
2.2. 实例与特征向量
- 实例是每个具体的输入。
- 特征向量是实例的一般表现形式。
2.3. 损失函数、风险函数、经验风险、结构风险
- 损失函数:度量模型一次预测的好坏。
- 风险函数(risk function):又称期望损失(expected),度量平均移一下模型预测的好坏。其定义就是一个数学期望的形式。
- 经验风险(empirical risk):又称经验损失(empirical loss),模型在训练数据集的平均损失。
- 结构风险(structual risk):在经验风险的基础上加上正则化项。
2.4. 正则化的理解
- 从贝叶斯估计的角度,正则化对应于模型的先验概率。
- 正则化项用于表示模型复杂度。
- 正则化项系数 \lambda ,用于平衡训练集上的训练风险和模型复杂度。
- 正则项系数较大,表示倾向于选择模型复杂度较小的选择;如果正则化项系数较小,表示倾向于选择模型复杂度较大的结果。
2.5. 泛化能力、泛化误差、泛化误差上界
- 泛化能力:模型对未知数据的预测能力。现实中经常采用测试误差来评价,但不准确。
- 泛化误差:是对应所学到的模型而言,即对 \hat{f} 来计算的,其形式与风险函数相同。
- 泛化误差就是学学到的模型的期望风险。
- 期望风险这个词好像之前书中没有出现过,按我的理解,应该就是风险函数或期望损失。
- 泛化误差上界:泛化误差的概率上界。
2.6. 条件概率分布与决策函数
- 决策函数:输入X,输出Y,预测结果就是Y。
- 条件概率分布:输入X,输出Y的概率分布,预测结果是最大化概率P(X|Y)对应的Y,即 \mathop{\arg\min}_{\theta} P(y|x) 。
- 生成模型和判别模型
- 生成模型:生成方法由数据学习联合概率分布,然后求出条件概率分布作为预测模型。
- 生成方法:可以还原联合概率分布,学习收敛速度更快。
- 判别模型:判别方法由数据直接学习决策函数或条件概率分布作为预测的模型。
- 判别方法:直接学习条件概率分布和决策函数,直接面对预测,准确率相对更高。
2.7. 极大似然估计与贝叶斯估计
- 极大似然估计
- 做什么用:
- 已知某个随机分布 x_1, x_2, ..., x_n 符合某种概率分布,如正态分布 X \sim N(\mu, \sigma^2) 。
- 但不清楚其中某个具体参数(如上述的 \sigma, \mu )的数值,记为 \theta 。
- 极大似然估计就是要获取 \hat{\theta} ,该 \hat{\theta} 使这个随机样本出现的概率最大。
- 具体做法:
- 给出概率密度函数。
- 给出目标函数,即似然函数,即若干个概率密度函数的连乘。
- 为什么是连乘?因为假设样本独立同分布。
- 为什么概率密度函数,而不是概率?
- 可以做一个等价,连续分布的概率密度在某一个点的概率密度为0,所以可以取一个邻域的概率,如下(其中 \varepsilon 是个很小的正数) P(|x-x_i| \le \varepsilon) \approx 2\varepsilon f(x_i)
- 对多个概率的的连乘,等价于多个概率密度函数的连乘再乘上一个常数,对于求最大值操作没有影响,因此可以通过概率密度函数来替代概率。
- 一般步骤:
- 写出似然函数。
- 对似然函数进行求导。
- 对参数求偏导。
- 令偏导为0,解似然方程组,求出参数的极大似然估计。
- 贝叶斯估计
- 最大后验概率估计:认为参数是一个随机变量,符合某个概率分布,求使得后验概率最大的参数值。
- 贝叶斯估计:
- 可以看做是最大后验概率估计的扩展。
- 认为参数是一个随机变量,符合某个概率分布,估计参数的分布,求期望。
- PS:虽然资料上这么写,但我怎么觉得各种贝叶斯估计求参数的值,都用的是最大后验概率估计呢……
- 一般步骤:
- 写出目标函数 L(\theta) = P(\theta | D) 。
- 取对数。
- 对参数 \theta_i 求偏导数。
- 解似然方程。
- 极大似然估计和贝叶斯估计的对比
- 问题相同:已知数据集D服从概率分布P,P中参数 \theta 未知
- 极大似然估计:
- 未知参数 \theta 是一个定值
- 未知参数 \theta 使得数据集D发生的概率最大
- \max P(D|\theta)
- 贝叶斯估计
- 未知参数 \theta 本身服从一定的概率分布|
- 数据集D发生的情况下,哪个 \theta 发生的概率最大
- \max P(\theta|D)
3. 课程习题
- 问题:推导下属正态分布均值的极大似然估计和贝叶斯估计。
- 假设数据 x_1, ..., x_n 来自正态分布 N(\mu, \sigma^2) ,其中 \sigma 已知,求解以下两个问题:
- 根据样本 x_1, ..., x_n 写出 \mu 的极大似然估计。
- 假设 \mu 的先验分布是正态分布 N(0, \tau^2) ,根据样本 x_1, ..., x_n 写出 \mu 的贝叶斯估计。
3.1. MLE
- 正态分布的概率密度函数为 f(x) = \frac{1}{\sqrt{2\pi}\sigma}\exp(-\frac{(x-\mu)^2}{2\sigma^2})
- 已知样本 x1, ..., x_n 来自标准正态分布 N(\mu, \sigma^2) ,写出似然函数以及对应的对数形式: L(\mu) = \prod_{i=1}^n \frac{1}{\sqrt{2\pi}\sigma}\exp(-\frac{(x_i-\mu)^2}{2\sigma^2}) \ln L(\mu) = k + \sum_{i=1}^n(-\frac{(x_i-\mu)^2}{2\sigma^2}) = k - \frac{\sum_{i=1}^n(x_i-\mu)^2}{2\sigma^2}
- 取最大似然(去除与 \mu 无关的项),即 \arg\max \ln L(\mu) = \arg\min \sum_{i=1}^n(x_i-\mu)^2
- 求 \mu 的偏导数 \frac{\partial}{\partial{\mu}}\ln L(\mu) = -2 \sum_{i=1}^n(x_i-\mu) = 0
- 得到最终结果 \hat{\mu} = \frac{1}{n}\sum_{i=1}^n x_i
- 思考:
- 当n足够大的时候,能够相信结果是准确的。
- 当n非常小的时候,跟真实的结果可能有较大的出入。
3.2. Bayes
- 已知独立同分布样本 x1, ..., x_n ,根据贝叶斯公式得到似然函数 L(\mu) = P(\mu|x_1, ..., x_n) = \frac{P(\mu)P(x_1, ..., x_n | \mu)}{P(x1, ..., x_n)} \ = \frac{P(\mu)P(x_1|\mu)...P(x_n|\mu)}{\int P(\mu, x_1, ..., x_n) d\mu}
- 我自己的理解
- 整个式子中,唯一的变量就是 \mu 。
- 分母为与 \mu 无关的常数,记为1/k。
- 分子中 P(\mu) 就是先验分布 N(0, \tau^2) (其实就是把 \mu 带入正态分布的概率密度函数)
- 分子中 P(x_i|\mu) 其实就是样本的分布,服从正态分布 N(\mu, \sigma^2) (就是把 x_i 和 \mu 带入正态分布的概率密度函数)
- 代入正态分布概率密度函数后得到结果 P(\mu|x_1, ..., x_n) = k \frac{1}{\sqrt{2\pi}\tau}\exp(-\frac{\mu^2}{2\tau^2}) \prod_{i=1}^n\frac{1}{\sqrt{2\pi}\sigma}\exp(-\frac{(x_i-\mu)^2}{2\sigma^2})
- 取对数得到(假设常数通过c表示) \ln P(\mu|x_1, ..., x_n) = c - \frac{\mu^2}{2\tau^2} + \sum_{i=1}^n(-\frac{(x_i-\mu)^2}{2\sigma^2})
- 求导: \frac{\partial}{\partial \mu} \ln P(\mu|x_1, ..., x_n) = -\frac{\mu}{\tau^2} + \sum_{i=1}^n(\frac{x_i-\mu}{\sigma^2}) = 0
- 得到最终结果 \hat{\mu} = \frac{\sum_{i=1}^n x_i}{n + \frac{\sigma^2}{\tau^2}}
3.3. 思考:
- 当n趋向于 \infty 时,与极大似然估计相同。
- 当n较小时,结果与极大似然估计较大。一般来说,此时贝叶斯结果较好。
4. 书本习题
习题 1.1
说明伯努利模型的极大似然估计以及贝叶斯估计中的统计学习方法三要素。伯努利模型是定义在取值为0与1的随机变量上的概率分布。假设观测到伯努利模型n次独立的数据生成结果,其中k次的结果为1,这是可以用极大似然估计或贝叶斯估计来估计结果为1的概率。
- 伯努利模型的极大似然估计:
- 模型:伯努利模型,即定义在取值为0与1的随机变量上的概率分布。
- 策略:最大化似然函数(等价于经验风险最小化)。
- 算法:不知道,计算最大化似然函数的过程应该怎么描述?
- 伯努利模型的贝叶斯估计:
- 模型:伯努利模型,即定义在取值为0与1的随机变量上的概率分布。
- 策略:通过贝叶斯公式获取参数的分布,根据分布求参数期望。
- 算法:不知道怎么描述……
- 用数学描述这个问题:
- 假设有随机变量 A \in \{0, 1\} ,其中 P(A=1)=\theta ,P(A=0)=1-\theta
- 现有n个样本,记为 A_1, A_2, ..., A_n ,问其中k次结果是1的概率。注意,这里的k是已知的,不是变量。
- 极大似然估计解答:
- 获取似然函数(即“一共n个样本,其中k个为1,剩下的为0”的概率) L(\theta) = \prod_{i=1}^nP(A_i) = \theta^k(1-\theta)^{n-k}
- 通过最大化对数似然函数来求解 \theta 的取值,即 \ln L(\theta) = k\ln\theta + (n-k)\ln(1-\theta)
- 求导取0后,得到结果 \hat\theta = \frac{k}{n} 。
- 贝叶斯估计解答:
- 根据贝叶斯公式得到目标函数 L(\theta) = P(\theta|A_1, ..., A_n) = \frac{P(\theta)P(A_1, ..., A_n | \theta)}{P(A1, ..., A_n)} \ \\= \frac{P(\theta)P(A_1|\theta)...P(A_n|\theta)}{\int P(\theta, A_1, ..., A_n) d\theta} \propto P(\theta) \prod_{i=1}^nP(A_i|\theta)
- 取 \theta 的先验概率为 \beta 分布,带入后得到(其中a, b为 \beta 分布的参数) L(\theta) \propto \theta^k (1-\theta)^{n-k} \theta^{a-1}(1-\theta)^{b-1} = \theta^{k+a-1}(1-\theta)^{n-k+b-1}
- 求导数取0得到 \hat\theta = \frac{k+a-1}{a+b+n-2}
- 另一种理解(没搞得特别懂,极有可能不严谨,仅供参考)
- 上式形式正比于参数为 a+k, n-k+b 的 \beta 分布。
- 贝叶斯估计得到的是 “关于参数 \theta 给定样本信息 A_1, ..., A_n 的后验分布”。
- 要在后验分布中寻找令后验分布的概率密度最大的点,即分布的众数。
- 参数为 a+k, n-k+b 的 \beta 分布的众数是: \hat\theta = \frac{k+a-1}{a+b+n-2}
- TODO:为什么选择 \beta 分布
- \beta 分布是伯努利分布的共轭先验(不太懂)。
- 知乎提问:如何通俗理解 beta 分布?
习题 1.2
通过经验风险最小化推导极大似然估计。证明模型是条件概率分布,当损失函数是对数损失函数时,经验风险最小化等价于极大似然估计。
- 用数学描述:
- 模型为条件概率分布模型: P(Y|X;\theta)
- 损失函数(策略)为对数损失函数,即 L(Y, P(Y|X;\theta)) = \sum_{i=1}^n -\log P(Y|X_i;\theta)
- 证明经验风险最小化等价于极大似然估计。
- 极大似然估计的形式(最大化似然函数): \arg\max_{\theta}\prod_{i=1}^n P(Y|X_i;\theta)
- 经验风险最小化形式(最小化经验风险): \arg\min_{\theta} \frac{1}{n}\sum_{i=1}^n -\log P(Y|X_i;\theta)
- 经验函数最小化形式等价于(去掉常数,通过负号修改 argmin 改为 argmax) \arg\max_\theta \sum_{i=1}^n\log P(Y|X_i;\theta)
- 而上面这个式子又等价于极大似然估计的对数似然形式。
- 所以经验风险最小化等价于极大似然估计。
发布于 2019-08-14 15:19
