BM25算法, Best Matching
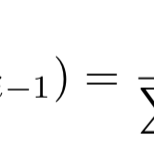
BM25是信息索引领域用来计算query与文档相似度得分的经典算法。
不同于TF-IDF,BM25的公式主要由三个部分组成:
- query中每个单词 q_i 与文档d之间的相关性
- 单词 q_i 与query之间的相似性
- 每个单词的权重
BM25的一般公式:
Score(Q,d) = \sum_i^n{W_i R(q_i, d)}
其中 Q 表示一条query, q_i 表示query中的单词。d表示某个搜索文档。
W_i 表示单词权重
这里其实就是IDF:
IDF(q_i) = \log{\frac{N-df_i+0.5}{df_i+0.5}}
其中N表示索引中全部文档数, df_i 为包含了 q_i 的文档的个数。依据IDF的作用,对于某个 q_i ,包含 q_i 的文档数越多,说明 q_i 重要性越小,或者区分度越低,IDF越小,因此IDF可以用来刻画 q_i 与文档的相似性。
单词与文档的相关性
BM25的设计依据一个重要的发现:词频和相关性之间的关系是非线性的,也就是说,每个词对于文档的相关性分数不会超过一个特定的阈值,当词出现的次数达到一个阈值后,其影响就不在线性增加了,而这个阈值会跟文档本身有关。因此,在刻画单词与文档相似性时,BM25是这样设计的:
S(q_i, d) = \frac{(k_1+1)tf_{td}}{K+tf_{td}}
K = k_1(1-b+b*\frac{L_d}{L_{ave}})
其中, tf_{td} 是单词t在文档d中的词频, L_d 是文档d的长度, L_{ave} 是所有文档的平均长度,变量 k_1 是一个正的参数,用来标准化文章词频的范围,当 k_1=0 ,就是一个二元模型(binary model)(没有词频),一个更大的值对应使用更原始的词频信息。b是另一个可调参数(0<b<1),他是用决定使用文档长度来表示信息量的范围:当b为1,是完全使用文档长度来权衡词的权重,当b为0表示不使用文档长度。
单词与query的相关性
当query很长时,我们还需要刻画单词与query的之间的权重。对于短的query,这一项不是必须的。
S(q_i, Q)=\frac{(k_3+1)tf_{tq}}{k_3+tf_{tq}}
这里 tf_{tq} 表示单词t在query中的词频, k_3 是一个可调正参数,来矫正query中的词频范围。
因此,BM25最终的公式为:
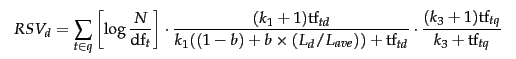
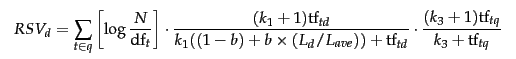
经过试验,上面三个可调参数, k_1 和 k_3 可取1.2~2,b取0.75
参考:
