
论做AI芯片的正确姿势

个人公号:RushPlayer
个人网站:https://rushplayer.github.io/
1 前言
因为种种原因中断了自己的几个AI项目后,我去做了AI芯片以求一个huge bless。也尝试了很多(ppt、code、optimize、AI算法、IDE、软件、IP、架构),但终觉姿势不对而修不得。或许做AI芯片应该践行阳明心学知行合一:知之真切笃实处即是行,行之明觉精察处即是知。
目前市面上号称AI芯片的公司百家不止,流片成功的也有不少,关于AI芯片的文章亦是全网乱飞,但大多对藏在细节里的魔鬼不惊不扰。同时看到不少关于AI芯片开源工程介绍,感觉更到位。
1.《我这个人不懂什么cpu,于是用代码模拟了一个》 2.《开源AI硬件的曙光:RISC-V+NVDLA合二为一》 3.《3天上手,30天精通!—— 深度学习FPGA加速器设计》
所以想象自己如果能不矫情不浮夸地写点东西也许有点意义,更能印证“知不易行不难,知行不分先后”之道理。
正如马云曾经说过:人生是一场各自的修行,修行路上遇见自己方得福报。


2 背景
直接举一个AI应用场景为例:MaskRCNN部署到IPhone做Inference。
2.1 MaskRCNN
MaskRCNN是一个非常典型且效果SOTA的深度学习网络,由FasterRCNN + FCN实例分割网络组成,一个网络涉及检测、分割、识别等三大视觉AI领域,有代表性。找了张图描述很到位,本想参考PlotNeuralNet编代码画得细节一些,到一半发现支持全部细节耗时耗力,纯属浪费作罢。

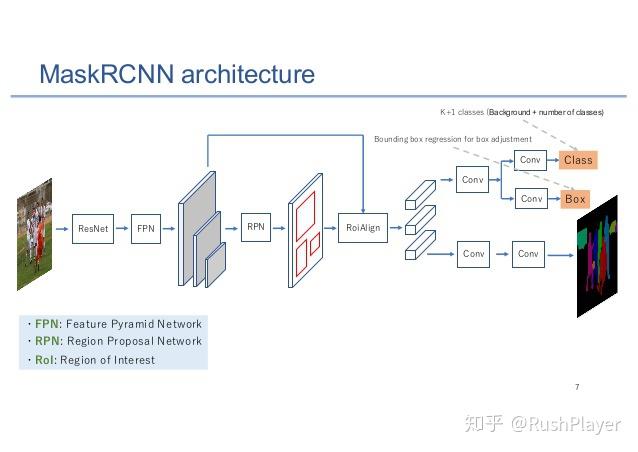
这里MaskRCNN我直接pytorch实现的Facebook官方范例,有几个特点:
- Backbone用了Resnet50配置,用残差连接跨块传递梯度,加速训练谈笑风生, 比一根筋的alexnent高不知道哪里去了。卷积基本都是3x3和1x1卷积,未用depth conv,也没有dialated conv,也没有deform conv等骚操作。
- 用了FPN多尺度提取,大小目标一一照顾。
- 直接借鉴faster rcnn的two stages操作,先粗检测再分割识别边框回归。也算是一种注意力机制,比one stage的ssd、yolo之类效果好。
- 计算量巨大,我大概算了下(考虑到卷积计算量占了绝大部分用MACs计)。以单张分辨率320x320的RGB图像输入算,Resnet50有28GMACs左右,FPN有11G MACs左右,复杂图像经过第一阶段RPN后,假设嫌疑目标数有100个是比较合理(一般上限也是100)。这样第二阶段对100个目标做FCN分割、边框回归和分类识别的计算量是43GMACs左右。
- 计算量之外也有一些逻辑操作,如NMS、排序、ROI操作等。
网络运算效果如下:


2.2 CPU(DSP)面对AI算法的囧境
IPhone是一个常见的部署平台,拥有优秀的操作系统和CPU。这里只讨论纯CPU运行,会涉及ARM的SIMD加速指令,不涉及到OpenGLES和coreml做GPU和NPU的加速。
算法移植到其他平台运行,需要从神经网络的解析、部署、优化一套流程,如果加上Backward 求导功能,就是一个完整的神经网络框架了。因为当年我自己把AI算法往IPHONE上怼过撸过一遍,后面软件章会简单说说。
取Backbone的Resnet50第一个block中最耗时的卷积层为例,图像输入输出都是64x160x160,stride=1,卷积核尺寸3x3,数据格式Float。取开源NCNN的neon卷积加速代码为例,一窥现代先进CPU工作方式。NCNN是一个Inference框架,优化性能在嵌入式AI业内也是有口碑的,SIMD指令调用、寄存器复用率、排流水并行、cache命中率都做得不错。


这段代码采用Sliding Windows直接卷积方法,未用im2col、fft、winograd等卷积加速法。采用64位neon指令加速计算,采用固定权重(Weight Stationary)方式,预先读取2组卷积核的部分到neon寄存器,这样输入图读一次可以做两次计算,复用一点是一点。单张输入图像一次读取4行8列,可以做2行4列8个输出点的3x3的卷积。一次循环最后可以获得2(输出图)x2(行)x4(列) =16个点结果。
附送几个IOS汇编优化的小技巧:
IOS做多核ARM的并行调用,没有现成的openmp。可以自己多开几个pthread划分数据简单并行,靠谱而且效率很高,也不用去管大核小核算力不同的同步问题。
现在的LLVM似乎也支持内联汇编配合C的用法了,如果感觉不适,可以用vfmaqlaneqf32之类的intrinsic汇编语法方便理解。如果还想要扣点性能出来,可以直接在.S文件汇编指令实现整个函数。
函数完成上述卷积层计算,要读数据1200M Bytes,写400M Bytes,核心循环有70条指令,所以总共要执行440M 条指令,就算指令cache、数据cache全部命中,每条指令都是单周期完成,这个卷积层也要花上440M个时钟周期。整个MASKRCNN最后跑下来几十秒一帧,这个效率基本上是废了。
可以发现指令驱动的机制限制了CPU算力发挥,SIMD执行单元很多时间都在空转。而更严重是指令单元占用CPU大量面积和功耗。如图所示,可以看出取指、译码、发射、执行等完整流程,执行只占用不到一成。就算CPU软硬件一起吃力地提高一点代码密度,少取几条指令,于事无补。也可以理解纯数据流0指令的ASIC为何如此省电。


现存大量设备还是这些CPU(DSP)居多,上面跑AI算法也是实实在在的市场需求。似乎也只能做算法精简和架构创新,如修改图像分辨率、用小卷积核、channels变少等简化设计、用depthconv+pointconv等方式。
CPU无能为力,主做图形计算嵌入式GPU?虽然号称算力10倍于CPU,但调用调试麻烦,算力也难发挥,可能最后跑下来还不如CPU。如果这么大计算量的网络要部署到端上芯片,怎么办?
是时候请出超级飞侠了,是AI芯片。
3 硬的
先不急,说几个我归纳的深度学习计算的几个特点:
- 计算方式简单:
- 最主要的计算是乘累加MAC,占据95%以上计算量,出没于FC、CONV、BN。
- 指数计算,广泛存在于激活函数sigmoid、elu,selu,softrelu、tanh等,还有loss函数softmax、BCE等,还有其他部分如VAE(可变分自编码器)对隐层的reparameterize。虽然指数可以通过泰勒级数展开乘累加实现。
- 数据流量巨大,但流向固定简单,少有if else 等逻辑判断,意味着可以预先优化数据流。
- 研究者巨量,所以带来各种骚操作层出不穷。如多变的卷积核1xN、Nx1、1x1、多变的卷积方式depth conv、dialated conv、deform conv、shuffle、胶囊网络等。


万物皆AI,能计算者皆可乘AI,,正如一位业内大佬之名言:哪怕一条内裤、一张卫生纸、一组光透镜都有它的用处。


3.1 算力提升之道
撇开DSA、算法软件定义硬件、聪明的软件愚蠢的硬件之类有的没的概念,AI芯片目的很简单:提升算力,降低面积和功耗。提升算力就是放多些计算单元,降低面积和功耗从上面例子看出减少指令的占比是个办法。具体方式我总结了3种:SIMD、SIMT、ASIC。 SIMD和SIMT属于指令复用,让同一个指令尽量驱动更多的数据计算,ASIC是通过固化数据运算和逻辑,不同程度地干掉些指令。当然所有算力的提升都会装到内存墙,内存系统设计更紧要,如多级cache、sram塞进pe、多路dma等。


SIMD
SIMD(single instruction multiple data)的特点是在核内做数据运算的并行,通过数据宽度增加提高算力。如Intel的simd指令集从MMX(64bits)、SSE(128bits)、AVX(256bits),还更极端的如ARM SVE指令集有做到了2048bits宽,相当于64个核并行(float32)。这种模式有几个缺点:
- 主要缺点就是SIMD指令太过复杂,如此宽的数据操作编译器自动矢量化无能为力,为难开发者手动汇编也不好做。
- 因为复杂指令系统依旧存在,simd指令设计又很复杂,额外增加了寄存器和cache,每个核都是巨无霸,想通过多核扩展提升算力性价比很低,而且SMP(Symmetric MultiProcessing)设计也并不容易。
这种模式一般提供算力在100Gops以下,主要玩家CPU/DSP。(如果SIMD只做GEMM或CONV计算,归类为ASIC)。
SIMT
SIMT(single instruction multiple threads)方法是把核做瘦后在核间做并行,32个瘦核绑在一个warp内共用指令控制,硬件做上下文线程切换。有几个特点:
- 核虽然瘦但是脱了有肉,内部设计也并不简单,也保留有取指译码执行等,一般也都会带128bits宽的SIMD(如nvidia ptx)。所以SIMT也不是会很省面积和功耗。
- 算力高了,容易撞墙,所以内存架构设计复杂。
- SIMT编程比SIMD简单,方便并行。
- 扩展方便,直接堆核算力可以到10Tops以上。
主要玩家GPU,从MIMD到SIMT的这条路GPU走了10多年,现在已经得道升天,称霸GPGPU市场。就像革命者最后都变成了当初自己反对的那一方,现在的GPU挑战者们也在这条路上。
ASIC
ASIC(application specific integrated circuit)零指令纯数据流的AI芯片没有见过,我猜原因可能是极端功耗敏感的场景,不深又不宽的深度学习网络效果还不如基于先验的传统CV、DSP算法。
大部分AI芯片都可算半ASIC化,放弃部分灵活性专门加速AI计算。
3.2 AI芯片的组成
做好深度学习网络的加速,一个科学合理的AI芯片架构,我总结了至少包含三部分:
- 矩阵乘加速,只做简单MAC操作,大算力专门加速FC、CONV。
- GPU单元,算力中等可编程,灵活支持不能MAP到MM单元计算。
- 调度中心,解决数据传输瓶颈,塞好塞满计算核。
3.2.1 矩阵乘加速
正如GEMM处在AI的核心,MM(矩阵乘,Matrix Multiplication)加速单元是AI芯片核心的核心,。我归纳了目前最主流的两种加速架构:“超宽SIMD”、脉动阵列。都由PE组成,每个PE自带register file和简单的控制逻辑。
超宽SIMD加速MM
这是最自然并行思路:PEs一字排开,从3块连续的内存挨个读写数据做MAC操作。至于pe间有没有交互传递一些数据看设计了。正如前面介绍的arm sve,只要实现2048bits FMLA simd指令,设计一下内存,做AI加速也不错。
脉动阵列加速MM
脉动阵列(systolic array)可以看作是2D的simd,是目前最密集的矩阵计算结构,广受好评,大批AI芯片公司采用这种架构,有google 、arm、nv等巨头。。下面两图描述比较清晰直接。




脉动阵列的优点:
- 2个维度最大化复用数据,从上传下PE间复用权重和partial sum,从左到左传PE间复用输入特征图。从邻居家拿数据,前后门传一下就行,不需要去共享大型sram取数据,省掉一堆寻址逻辑,数据能耗更低。
- 控制简化,布线简单,省下的晶体管资源,频率也更容易做高。
- 高效支持FC层和CONV层,只要互换WEIGHT和Input的处理方式。
- 该架构易扩展,多片并联或者单片增减脉动阵列尺寸很方便。
有一个问题,脉动阵列由于尺寸和形状固定,数据会不会喂不饱?如TPU的256x256脉动阵列,当遇到FC层输入输出节点少、1x1的卷积核等情况,reformat数据就能?是否可以将"权重"固定在weight register上传下只要传partial sum?还有要延迟256周期才能有第一个计算结果,对于大计算量的网络层算不值一提。
arm做了一个名为SCALE-Sim( Systolic CNN Accelerator Simulator)的工具,从PE阵列大小和形状、数据流不同映射方式、sram大小和带宽等多尺度来模拟评估性能,以便找出最佳配方的脉动阵列。
我一个猜测:未来有3DSram基础上3D脉动阵列。
举俩例子
硬件实现好了,至于怎么利用那又是另外一篇文章。比如卷积用滑窗(sliding window)、im2col、winograd、fft都可以设计,图像是要切块、切片、切条?切多大多厚也要测试。。。。都不容易。举两个例子:
- 开源的NVDLA,内部MAC以1024bits宽并行计算MAC,硬件实现CONV、FC、Pooling、激活等层。有个基于AWS FireSim的开源项目,就用rocket + nvdla 做了一个AI芯片。
- NVIDIA的tensor core,volta架构每个SM(stream multiprocess)多了8个这玩意,一个周期完成4x4矩阵的乘累加共64个MACs,听说内部是个小型的脉动阵列,有 SIMT、SIMT、脉动阵列 三种设计。还开放接口(WMMA)供用户灵活调用,CUDNN、CUBLAS也不在话下。


3.2.2 GPU
这部分主要特点是可编程算力,灵活支持各种日常所需,还有一个目的买一送一打开市场,让客户感觉买了AI芯片还送一个DSP(GPU),毕竟NVIDIA都在买一送二:买NVDLA送CUDA再送TensorCore。 算力设计有几个点要考虑:
- 根据各自负责的算法算力比例,相应设计GPU和MM加速单元的算力比。
- 根据可能的应用场景算力需求,如传统CV算法、音频算法、传统机器学习算法等。
举个例子,假设端侧AI芯片总共有4Tops算力,那这个GPU分个400Gops很ok。其实每个场景都不一定,全凭经验和理解。
计算格式最好能够支持int8、int16、fp32三种(fp16不要的原因后续),提供几百Gops的算力,还要方便用户调用做并行计算,只能上SIMT架构了。通过支持OPENCL标准,对接大量成熟opencl开源工程。如果SIMT每个并行小核也设计了宽度不等的simd,更考验编译器水平。
3.2.3 调度中心
AI计算特点之一就是巨量数据的存取,这部分占整体能耗很大比例,尤其是通过总线的dram,高延迟严重拖累整体效率。解决办法就是设立一个调度中心,包含DataProcessor、内存系统,是整个芯片设计最复杂最需要优化的。
DataProcessor主要做深度学习网络的reshape、flatten、slice等数据搬运操作。根据计算复杂度和GPU配合,做一些数据的reformat,如deform conv、winograd、脉动阵列、padding这些操作之前的transform。还有很多AI芯片放在GEMM单元后面的BN、Pool、激活层硬件单元,是不是可以去掉在这里搬运时顺道做。
内存系统包含:DRAM、SRAM、DMA等。DRAM在片外,容量大传输慢一般也就100GB/S,Sram在片上纯晶体管组成,容量小传输快以10TB/S起跳,DMA绕过CPU直接从内存存取数据。在AI芯片上和传统CPU有几点不同:
- 因为AI计算数据流相对简单和固定,Sram采用ScratchPad Mem组织,有自己独立的地址空间,计算单元直接操作。相比常见的Cache设计,可以省下Tag、比较逻辑,也不需要组相关全相连之类的map预测逻辑,更不用L1、L2、L3这种多级设置。
- 同样是因为数据流简单固定,DMA的主要工作可以是DRAM和SRAM之间的数据传输。
- samrt DMA、内存同步,双缓冲等等之类,我也不知道怎么做,”知“的功夫还没达到”行“的境界。
3.3 其他
ZeroSkip:主要是利用数据的稀疏性加速运算。细一些就在MAC内部做非零判断,粗一点直接做稀疏表达矩阵乘,后面软件部分会再聊两句。
关于MAC多精度设计:现在业内关于低精度深度学习网络的研究也是热门,MAC支持低于8位的int1、int2、int4等格式,除了可以刷TOPS/W去吹牛B,也是有点实用价值的。不管是加法树、查表法实现乘法器,多精度支持的关键在于复用,尽量减少额外的芯片资源和能耗。另外不同的精度也需要相应调整PE阵列、带宽、SRAM等。如下图是今年一篇论文的AI芯片研究,通过配置带宽、脉动阵列、MAC精度等参数来适应不同的深度学习网络。


PileLine:实际应用场景包含各种算法、AI网络层,都可能map到CPU、MM加速、GPU等计算单元上,在处理视频的连续帧,就可以找机会做帧间PipeLine,如前处理和后处理等流程。
存内计算:因为内存上数据搬运和芯片上数据计算都是晶体管状态改变,直接把数据存取、计算合一起做了,比较高调的http://mythic-ai.com 和http://syntiant.com。其实在FPGA应用常见,把Register File放进PE内也算一种内存优化:“近内存的计算或近计算的内存”。
类脑计算:忆阻器直接模拟大脑神经元,电阻作权重电流电压作输入输出。
模拟计算:传感器直接模拟信号低精度运行,不知道要不用加AD/DA。这几天新闻热点导电碳纳米管做的RISC-V芯片。
更屌的光计算:《几乎零能耗零延迟:UCLA发明光衍射神经网络》,《光速执行AI运算,港科大双层全光学神经网络不要计算机也能做分类》,虽然现在很原始,但这也许超越碳基、硅基的另一种文明思考方式。


这些现在都是科研热门,在资本市场也很吃香,很可惜我不懂。
4 软的
AI芯片讲究软硬一体说学逗唱,无论是卖IP授权、卖芯片、卖开发板、卖解决方案,芯片参数之外,一个友善的开发环境是客户最有感的东西,包括操作系统、驱动、IDE(图形化界面、profiler、debugger等)、python/c/c++多种接口、自定义网络层(python、c接口,map到最合适硬件)、提供的demo细粒度可从应用->网络->网络层等。开发环境可以分阶段,比如先c/c++接口再提供python,比如嵌入式场景python是否合适?图形化IDE要不要?图形化神经网络这个噱头怎么吹?联机调试、指令模拟、交叉编译能不能省?
硬件是少林功夫傻大黑粗练就对了,软件是唱歌跳舞观众有感,更需要身段透软、形象嗓音面面俱到。就算都做好了也上了台,也可能会被啤酒瓶砸头,然后看有人在台上唱、跳、rap和篮球,号称练习了两年。


4.1 自研AI框架是必需品
AI框架包含训练和推理,毕竟云端训练需求的都是土豪,我没体会过土豪们的快乐,所以大部分时间可能都说的是Inference。
自研AI框架是必需品几个理由:
- 简单。因为深度学习算法由简单而暴力的算法堆砌,动手撸一个自己的框架并不复杂。所以现在写的不错开源框架遍地开花,甚至很多只是程序员业余时间开发。以Inference为例,无非是parse其他框架的模型,然后deploy到自己的平台上。如果是别人的平台,以我之前在IOS的先撸为例,CPU(NEON)、GPU(OpenGLes、metal)、NPU(CoreML)各种计算资源用起来要费点心思。
- 安全。自研框架自定义格式方便客户加密深度学习网络。
- 方便。相比照搬开源AI框架实现,自研框架更方便集成到软件开发环境,如Debgger、Profiler等,也更方便在自己硬件上发挥。
4.2 AI编译器 ?编译器AI !
有人喜欢形而上提概念:用“AI编译器”编译AI网络。我看好像只是一个Inference框架而已,言必称编译器过度解读了。原因:
- 传统编译器支持x86\arm几个硬件即可,而AI加速硬件实现有几十上百,自己不可能去自适应,要AI芯片公司自己来配合你标准的动机不够。
- 如果自己再硬凹一个开源硬件加速器去搭配这个编译器,感觉本末倒置因果颠倒了。
- 再说想要一个一劳永逸的AI编译器,并不能预知未来的AI进化成什么样子。
我觉得可以反过读编译器AI也许有价值。用AI改造训练传统编译器,智能排流水、智能利用寄存器、智能矢量化、智能预取提高cache成功率等提高优化GCC、llvm编译效率。汇编这个活请不到那么多三哥偷偷在后台做,不会有类似这样的造假《用印度码农冒充AI,这家明星公司挣了1个亿》。
4.3 自研AI框架实现
AI框架包括parser、内存管理、计算管理。可以集邮票这种一点点收集的形式来实现,开始多一些if else可以容忍, 毕竟AI网络都很简单,做得多了再去归纳总结标准化也不迟。
Parser模块功能是解析各大框架的网络,如果自己一个个去支持(mxnet、torch、darknet、chainer、paddle、tensorflow、keras、pytorch..),特别是不幸遇到tensorflow,其上百种类型几千个节点组成的静态图网络,吐血。不如先通过支持一些大公司推的中间标准格式,如onnx、onnx等,来的省事,当然用户看不到onnx这层。
内存管理有几个要点:
- 采用预分配技术,需要分析整个网络架构,理想情况是网络运行前malloc,运行中填空,结束后free,尽量减少无意义的memcpy操作,Inplace到极致。如resnet的block的ADD操作,第一个conv的输入可以作为最后一个conv的输出。
- 只是设计一个内存池来管理?但耗时的不是malloc free操作而是读写操作。
- 调度DMA,做SRAM(ScratchPad Mem)和DRAM之间的拷贝。
计算管理主要映射、融合和优化。优化部分放在后面一节单独聊几分钟。
映射是根据各个网络层的特质映射到相应的计算单元(主控CPU、data processor、gpu、mm)运行。如逐像素的计算图像均值方差、MM之前的transform操作、众多的指数操作、NMS、RPN、视频处理时前后帧的PipeLine。
融合最常见的是Activation函数融合到NORM、CONV、FC之后,省下一次内存的读写,还有如nearest算法对图像做2X的Upsamle操作也可以融合到其他计算,可融合的其实也不少。但是如果不同层map在不同计算单元上,就不好协同融合,更多是以硬件形式融合了,如TPU在Accumulator之后接了硬件的Activation和Pool。
再随便说几个细节:
- 留好backward接口,考虑周全些也许哪天被土豪云看上了。
- Deconv层,有Transposed conv、分子卷积(stride<1)等多种叫法,常在encoder-decoder网络的decode时做upsample用。光从多个名字就能猜出不同框架实现不同,有的是先对输入图upsampe填充0再正常卷积,有的先正常卷积再对输出图upsample填充0。做算法Deploy需要注意,如果是调包侠可以用upsample(nearest)+ 正常卷积替换,效果更佳。
- Instance Norm层,Inference时用Training过程的runningmean和runningvar效果会很差,尤其是图像检测和分割。宁可一张张单独算mean和var,虽然添加了计算和并行流水架构被打乱。Batch Norm层可能是因为channel数多,直接用running倒没那么糟糕。
4.4 AI计算的优化
主要是讲CONV的优化,FC计算实际MACs不多,优化更在于巨量的weight稀疏性的利用,FC层的权重和输入互换成1D-CONV,可以运行在MM加速单元。
CONV计算可以分两种:1. 输入图像和卷积核转换成矩阵进行相乘。2. 直接滑窗实现。
转换成矩阵乘的好处之一就是方便支持各种奇奇怪怪的卷积,在transform就做了dialation、stride、deform、pad、非对称卷积核等处理,但会多几个数据Transform和额外的内存读写。直接滑窗可能不需要Transform和额外内存读写,但优化起来卷积方式相对受限,如stride、dialtion等逻辑在卷积过程处理的话,可能影响效率。
关于数据流格式和数据复用,脉动阵列、tensoecore这类相对尺寸固定,权重和输入图像固定了流向,已经最方便的复用了权重和输入图。心思更多是怎样对数据切分和Transform,使之与脉动阵列达成最和谐的姿势。
关于优化切分:
昂贵快速的SRAM不放不下所有FeatureMap、output、FC层的weight,必须要做切分。至于切块、横切、竖切怎么选,要考虑输入图像分辨率,channels 、Transform方式、CONV计算方式、MM加速器的尺寸、Sram大小、带宽等综合考虑。有时候是多种切法的组合,有时候不是切而是拼接。要保证切分后的网络精度,需要对图像进行无痛切分:在开刀处把邻居像素作为pad存下来,这样才能即无痕又不影响工作。
winograd:
winograd是一种降精度的卷积加速法,加速如3x3的小卷积核卷积。需要对输入、权重、输出做Transform操作,Transform可以由简单的移位和加减法组成。有一篇文章Sparse winograd cnn on systolic array,研究在脉动阵列上做winograd卷积。
Winograd计算如图所示,图像中每个2x2的块扩到4x4再Transform,3x3的卷积核Tranform到4x4,一阵倒腾后做矩阵乘,最后再对矩阵乘结果做Transform,图中还考虑同时做了输入图像Channel间的复用,有的开源winograd实现并没有这么做。通过转换,只要16个乘法就能得到4个点输出,正常卷积要36个。但多出了Transform的开销,需要衡量该开销和MACs减少带来的收益。加上Winograd总归是一种降精度近似计算,在已有的AI芯片方案中实际应用的好像也不多。


FFT加速卷积:
快速傅里叶变换对图像分块做8x8或16x16的FFT蝶形运算,卷积核也要略大一些好映射到相应尺寸。但现在大卷积核在深度学习中并不流行,FFT加速卷积的应用不多。
4.5 其他
4.5.1 量化(INT8)
因为方便上手也为容易讲清楚,这里只讨论int8量化,其实嵌入式AI业内做低于8位的深度学习也是大热门,如int1(二进制)、int2、int4等,二进制网络见过几个团队做效果不错,int2、int4精度现有CPU、DSP、GPU无力支持,只有FPGA上实现。
关于浮点和定点:定点的表达逻辑比浮点简单很多,反映在芯片资源和功耗都是数量级的差距。测试过INT16模式运行完整网络,精度不差于FP16。
下面聊聊量化的几个知识点:
- 深度学习网络各种norm层(BN、IN),激活层(relu、selu、sigmoid、tanh)广泛分布,输入特征图、weight常浮在是0-1附近。我简单统计了一些网络的权重值分布,一般单层SUM值差不多都在10左右,INT32 = INT8xINT8 + INT32 无溢出之忧。
- 网络训练一般learnin grate都从0.001甚至更小起步,一点点迭代抠精度。如果要以INT8训练,要修改训练框架的GPU加速部分,用浮点硬件模拟定点运算。
- IEEE浮点数表达方式比定点复杂太多,int8代替fp32省下的除了看得见的24bit,在芯片资源占用和计算能耗都是数量级的提升。
- 秉持不麻烦客户的原则,所以现在int8量化都是post training阶段,只要网络和一些样本直接一键量化。


受益于深度学习网络的鲁棒性和冗余性,量化得当一般精度降低范围可控。现在有不少开源的int8量化方案,很多应该源自TensorRT,实现也大同小异。分为对称和非对称两种方法,以CNN卷积层为例。
- 对称算法应用于weight量化:
- 找出group内权重绝对值最大值absmax.
- scale =127 / absmax .
- 对weight进项量化: weight=weight * scale.
- 非对称算法应用于activation量化: 处理激活值稍麻烦,我也试过对称算法,直接按照absmax量化效果非常糟糕。因为激活值分布范围广,也不如weight规整。
- 跑几张样本,保存所有的激活值,然后flatten()操作拍平成一维数组A,找到数组A最大绝对值absmax.
- 计算直方图间隔单位值,histinter = absmax/bins,这里先设定bins =2048
- 将数组A按照histinter 间隔计算直方图。如果该absmax是一个很大的孤立点,那么会出现这张直方图都会落在左边一点点位置,明显很不均匀不ok.
- 在2048里面找出一个值T,将[0,T]区间的直方图分布作为一个分布P,然后把P分成128份做一个bin=128的直方图P1,然后把P1缩放成一个bins与P一样的分布Q,用P1的均值作为Q的值。然后计算P和Q的相对熵。
- 通过循环找到一个点T,让P和Q分布最相似。根据直方图P中T位置的边界中最大绝对值作为absmax。
- scale =127 / absmax ,卷积计算时输出值量化 act = act * scale.
不同的网络层类型和超参数,量化方式都要谨慎选择一一尝试找出最优解。如CONV层输入图像太大、channel数多、FC层输入节点太多等情况下,保证网络精度的考虑,是不是不量化了,或者量化到INT16。不同芯片平台量化方式也有不同考量,比如是否FP32、int8、int16多种格式,而且不同格式间是否复用、算力有没打折,选取最具性价比的一种混合精度模式。不同应用场景,有不同的精度考量,比如图像按照量化敏感度排:识别分类<目标检测<图像分割,语音NLP领域,RNN、GRU、LSTM等全部FC层更要用心对待好好相处。
4.5.2 稀疏、剪枝和蒸馏
AI网络的稀疏性产生,就像人类大脑年岁渐长大脑神经元连接变得固定,去掉很多神经元连接,所以异想天开的能力只存在那天赋异禀的少数。


FC层关注权重的稀疏性,CONV层关注激活输出的稀疏。但是现在VGG里4096x4096类似规模的FC层不太在新网络架构出现,用conv层来代替fc层的也不奇怪。尤其是嵌入式AI领域,消除FC层稀疏权重是目标,认识一个做KWS(keyword spotting)算法加芯片的团队,一直揉网络挤压尺寸从几M到几百K。
而CONV层卷积核参数本来就很少,之前由于因为relu引入造成输出的大量稀疏,但是现在prelu、selu之类加入抢救了一下负激活值,整个网络效果还提升不少,所以我倾向当CNN网络run起来是不稀疏的,再说稀疏性和winograd、im2col、fft之类transform再gemm的加速方法八字并不合。
如果retrain做剪枝(删除小权重再找跑几个epocs微调剩下的权重,属于算法训练领域,调参师调包侠们的多调一个包,但是让算法变得硬件友好他们并不在意。基于不麻烦客户的前提,如果不retrain剪枝完后精度怎么保证?对着客户动辄几百M上G的网络,FC层稀疏的权重真的置之不理吗?有几个办法:
- 在inference之前对权重进行处理,做行标、列标的Index数组,进行稀疏表达下的矩阵乘法。常用的如CSR/CSC(Compressed Sparse Columns/Row),用前面非零数值的个数代替行(列)下标压缩。
- 在MAC内部做zero skipping。
- 权重做Huffman压缩,计算换时间,这些逻辑多少会占用芯片资源。
- FC层输入输出节点不能删减情况下,只是去掉小参数的连接,计算不均匀的情形怎么办?如用深鉴的论文介绍,如何对非零权重重新分组排列适配并行PE处理?
秉持Risc不过度设计的宗旨,我觉得AI芯片要不要做剪枝可议,理由如下:芯片做深度学习推理时,FC层大概率也是CONV层顺序执行的,FC层完全可以复用conv层的硬件计算资源,脉动阵列对于GEMM的效率早已经过严峻考验,带宽、sram、PE已经准备好迎接FC层。只要简单改下逻辑:把FC层的权重当作CONV层的输入图,FC层的输入节点当作CONV层的卷积核。
知识蒸馏,压缩大网络变小网络。怎样减少卷积层channel数、卷积核尺寸、fc层节点数?本就不稀疏含水量不多的网络怎么蒸馏映射?需要Retrain的话训练策略方法改不改?大堆细节。最后还不如重新训练一个小的?!各大会议和媒体上吹水常见,但实际应用没见过。
5. 生态
5.1 拥挤的赛道
《一文看全:全球99家AI芯片公司全景图,中国正在崛起》这篇文章列了99家AI芯片公司,赛道拥挤。我也随意聊几个曾经评估试玩的芯片:有CPU、GPU出身的,算力从10G、100G、4000G都有。也包括插电、电池供电、PCI-E板卡等环境,都有个普遍特点:软件都不是很好用。。
某A团队,专做语音识别方案,算力要求不高(RNN、DNN、LSTM),采用CPU加HW GEMM,也跑得挺溜。 某绿浪公司GAP8,1个risc-v主控大核加7个risc-v从动大核,都含32bits宽的SIMD做4个int8并行加速,共享指令cache,硬件同步,再加一个HW CONV单元。倒是挺省电的,算力10Gops(int8)。感觉像mimd到simt的第一步。


某Esperanto公司,走的更极端目标更远大:直接要用risc-v挑战intel、arm、nvdia。16个64位的高性能rv大核当CPU,完整的L1 L2cache设计,4096个rv小核并行做当GPU。大小核都带64位simd指令处理。带shader编译器可吃鸡,带不知道加速什么的ASIC,不知道4096个小核并行画面烫不烫?随意搜了下,只有一个2017年名为simty的项目,将已有二进制程序的RV指令MAP到SIMD和SIMT硬件,但SIMT riscv又在哪?基于risc-v的开源GPU个人有点期待。
还有和某GPU公司玩的较多,篇幅有限就不介绍了。有一些在区块链割韭菜来做AI芯片,而且cloud端、edge端都做。感觉怪怪的,不知真假动机。我的另一篇 韭菜AI大逃杀。
5.2 BenchMark不服跑个分
AI芯片辣么多,挖掘技术哪家强?固定输入参数,跑钦定的网络层,刷Tops/W指标,除了去会议媒体吹,这种细粒度完全没有意义。不如选择一些典型识别、检测、分割网络,用roofline模型定义好神经网络的算力和数据带宽比例再跑或许科学一些。能整个网络run说明软件对于网络deploy初步过关。不细究硬件架构如何,按照fps数一排列立分高下,不服也不行。如果能再上一层跑实际深度学习应用场景,多个网络结合传统算法和一些逻辑处理,考验cpu、dsp、音视频编解码、ISP等综合SOC能力,这种benchmark客户会更有感。
BenchMark这种没啥技术含量但又有曝光度的好事情,小米、阿里、腾讯、fb等公司都争着开源了不少工程,现在也没啥标准。
5.3 做芯片不赚钱就是交个朋友
接触过的一些行业,随意聊聊。行业生态直接决定了芯片进展,如手机人脸快速识别这个高频需求,才算直接催生了AI芯片在手机领域的流行,因为GPU/CPU的性能和功耗都不达标,3D结构光人脸快速识别的需求催生了苹果的A11 NPU,安卓跟上了寒武纪、谷歌visual core、高通等一众AI芯片,随之而来便是手机应用一波AI革新:人脸识别、场景识别、场景分割、相册图像理解、ocr 翻译、语音助手、离线翻译、AI相机等。
SOC是AI芯片存在形态,根据应用选装集成如主控CPU、音视频编解码及采集、蓝牙、wifi、usb、pci-e、axi、hdmi、mipi、stat、tf、arduino、ISP单元、视频运动检测等。还有一种不多见是外挂NPU扩展已有SOC的AI能力,瑞芯微似乎就外挂了一颗芯原NPU。SOC形态中,如果能把AI计算那部分DSP能力开放出来加分不少,需要考虑怎样的接口方便用户调用做一些传统信号处理算法,如边缘检测、插值缩放、直方图统计、模板匹配、色彩转换、去噪等。
云计算领域的AI芯片,谷歌、AWS、阿里云等土豪自研自用,传家宝不外泄。提高与nvidia议价能力,3万单价的NV计算卡和3千的游戏卡怎么算成本?更重要是这一套完整的芯片研发流程,搭建起硬件设计、前软后端流片、编译器、AI算法、AI框架等整套闭环生态,一支高大上形象科学的研发团队呼之欲出,所以傻子才不做AI芯片。这里AI芯片算法训练是主流,需要backward prop,内存需求高一个数量级,软件开发把芯片算力嵌入tensforflow、pytorch、caffe等开源框架最佳,不过大佬们都有自己深度学习框架,更方便集成和定制。
云计算需要AI芯片灵活缩放能力、虚拟化、弹性化。缩的能力代表单芯片分割并行计算多网络分割,怎么切分PE阵列、分带宽、分sram?灵活缩放代表多芯片相连分布式计算扩展(通过以太网口、NVLINK),硬件可以通过以太网口(nvlink)交互,软件上传统方法是采用一个参数服务器+多个计算终端模式中心化设计,逻辑简单效率低。比较创新去中心化设计如的tensorflow的Ring All-reduce算法(scatter-reduce + allgather),多个芯片组成一个一维或者2维环,每个芯片的分块计算结果在其中流动,都是从左(上)邻居拿数据,传数据给右(下)邻居,类似脉动阵列partial sum概念传递梯度,芯片内部和外部如此相似设计,说明重复和对称才是宇宙秩序和天理。


再聊一个AI视频云处理场景:用户上传原始视频、服务器解码视频、按帧识别检测NSFW(鉴黄师)、人像分割(避免弹幕糊脸)、物体商品场景识别(视频标签、流量变现、多帧视频做时序分析(还不成熟)。此时芯片需要提供强大的AI计算能力之外,还要附带相应的多路音视频编解码ASIC。竞品NVIDIA集成了NVENC/NVDEC,FPGA移植个RTL的事。


聊聊无人车、无人机、机器人,见最多还是成熟的GPU方案。不管规模大小的似乎每家公司都有自己的AI芯片计划,和互联网云巨头们类似:如果能够每年卖很多台,一台车俩AI芯片自研AI芯片这生意怎么看都不亏,如果卖不出量,AI芯片概念在上市财报还是给投资人看,会有人买单,找别人现成的AI芯片方案冠个名也只是小钱。接触过几个无人机无人车团队,感觉技术方案里AI成分都不多。
聊聊Deep-Q-Learning(强化学习、CNN)的应用,这种输入图像输出操作的模式在游戏中也许可以,一天迭代几百万次,现实世界由没人会用这黑箱来做决策。常见还是深度学习提取特征然后再用逻辑判断(也没有Q-table)。无人车为例:普遍多摄像头融合、多传感器融合后进行深度学习提取特征,如采用激光雷达点云卷积、双目融合、目标识别、目标检测、实例分割等技术,再判断车道、行人、标志、车辆等信息。无人车在现实环境中在线无监督训练学习,当前好像也没这需求,车载AI芯片暂时也不用考虑backward propagation。
还有其他功能如NLP智能对话、导航规划等对于算力的需求不大,端云配合双保险,断网也OK的。
语音识别激活kws(keyword spotting),速度要求实时同步采样帧率,算法复杂但计算量不多,交给DSP靠谱,如多阵列麦克风降噪合成。有的是电池供电场景功耗极端敏感,cpu+dsp/GEMM技术方案灵活选择,DNN小网络int8量化最好retrain。
关于FPGA:1.作为IC开发的验证工具、开发平台,也是各大”AI芯片“公司们的“产品实体”。2.在云计算和端侧,都是属于高端货。如云计算一块算力4T的PCI-E的fpga计算卡能卖2万多,蹭NVIDIA高价计算卡。edge端也是无人机、高级摄像头的存在。
嵌入式领域AI芯片,基于数据实时性、安全隐私和成本考虑,不方便上云运算。包括各种设备的智能升级,如音箱,冰箱、安防IPCamera、DVR等,检测识别人脸、人体、车辆、物体、灾情、动作等等。嵌入式AI这块我做过一些工作有点思考,不少考验:
- 考验AI芯片的裁剪能力,相比云计算高能版本,端侧精简版会不会费事费力二次开发?
- 考验SOC集成能力,需要:CPU甚至GPU(如带屏幕交互、人脸库快速存储检索)、音视频编解码ASIC、运动物体检测ASIC(光流角点计算)、DVAFS动态电压调频、休眠技术(always on省电场景)等。
- 考验算法优化能力,嵌入式可能会面对精简版AI和传统CV算法两种选择。支持传统CV算法,需要对如haarlike特征提取、积分图、人脸识别、卷积等计算热点加速,映射到AI芯片的GEMM单元,或是DSP单元来加速?
- 考验IOT、AIOT、lora、nb、liteos...上来就能一顿胡扯的能力。
5.4 AI芯片创业是机会?
快速迭代的AI算法引领着行业的变革,老旧的芯片架构和工艺要跟上适应节奏。但AI芯片是基础设施,中小创业者的冒然闯入是机会?要活下去必须灵活应对市场和资本的瞬息万变,待客户和投资人如衣食父母,有理想要上进必须需要具备“全栈”能力:行业市场大局观、深度学习算法长久耕耘、芯片架构专家突破旧俗、前端后端尚可外包、软件开发环境、操作系统借助开源也要自己集成。一套昂贵的veloch仿真工具只是零头,人力开支,IP开支,流片前后端研发、流片封装测试,够烧到哪一步?后面商业推广顺利否?好不容易做出来,发现比NVIDIA、intel、海思等大佬的产品差一截,落个为国流片的结局,回想当初做矿机芯片割韭菜是什么结局?


传统芯片公司的慢节奏正被互联网公司带了节奏,玩敏捷开发(用户需求、快速迭代、模块化、标准化)。行业先知DARPA预见了变革,推的项目CRAFT(Circuit Realization At Faster Timescales),目的集成电路快速定制、标准化做到加速开发。
创业关于3D脉动阵、存内计算这些高端货创新,没资本驱动中小创业公司能不能活过一集?帮客户训练算法、编软件、嵌入式移植、端云结合的开发都是偶一为之的。卖IP授权的公司替客户做IC design,蹭国产AI芯片的热点,也是种商业模式探索。有心做或许反而在其他领域栽柳柳成荫。