
分布式机器学习之——Spark MLlib并行训练原理

这里是 王喆的机器学习笔记 的第二十五篇文章。接下来的几篇文章希望与大家一同讨论一下机器学习模型的分布式训练的问题。这个问题在推荐、广告、搜索领域尤为突出,因为在互联网场景下,动辄TB甚至PB级的数据量,几乎不可能利用单点完成机器学习模型的训练,分布式机器学习训练成为唯一的选择。
在笔者看来,分布式机器学习训练有三个主要的方案,分别是Spark MLlib,Parameter Server和TensorFlow,倒不是说他们是唯三可供选择的平台,而是因为他们分别代表着三种主流的解决分布式训练方法。今天我们先从Spark MLlib说起,看看最流行的大数据计算平台是如何处理机器学习模型的并行训练问题的。
说起Spark,我想不会有任何算法工程师是陌生的。作为流行了至少五年的大数据项目,虽然受到了诸如Flink等后起之秀的挑战,但其仍是当之无愧的业界最主流的计算平台。而且为了照顾数据处理和模型训练平台的一致性,也有大量公司采用Spark原生的机器学习平台MLlib进行模型训练。选择Spark MLlib作为机器学习分布式训练平台的第一站,不仅因为Spark是流行的,更是因为Spark MLlib的并行训练方法代表着一种朴素的,直观的解决方案。
Spark的分布式计算原理
在介绍Spark MLlib的分布式机器学习训练方法之前,让我们先回顾一下Spark的分布式计算原理,这是分布式机器学习的基础。
Spark,是一个分布式的计算平台。所谓分布式,指的是计算节点之间不共享内存,需要通过网络通信的方式交换数据。要清楚的是,Spark最典型的应用方式是建立在大量廉价计算节点上,这些节点可以是廉价主机,也可以是虚拟的docker container;但这种方式区别于CPU+GPU的架构,或者共享内存多处理器的高性能服务器架构。清楚这一点,对于理解后续的Spark的计算原理是重要的。
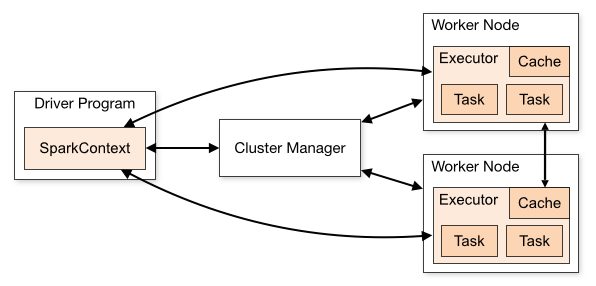
从图1的Spark架构图中可以看到,Spark程序由Manager node进行调度组织,由Worker Node进行具体的计算任务执行,最终将结果返回给Drive Program。在物理的worker node上,数据还可能分为不同的partition,可以说partition是spark的基础处理单元。
在执行具体的程序时,Spark会将程序拆解成一个任务DAG(有向无环图),再根据DAG决定程序各步骤执行的方法。如图2所示,该程序先分别从textFile和HadoopFile读取文件,经过一些列操作后再进行join,最终得到处理结果。
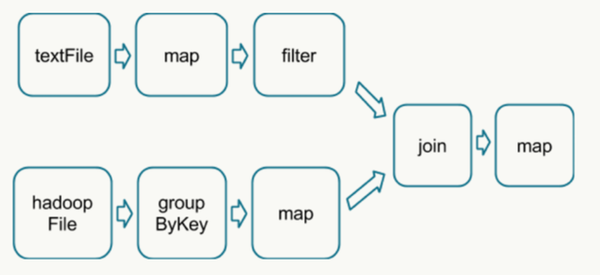

在Spark平台上并行处理图2的DAG时,最关键的过程是找到哪些是可以并行处理的部分,哪些是必须shuffle和reduce的部分。
这里的shuffle指的是所有partition(数据分片)的数据必须进行洗牌后才能得到下一步的数据,最典型的操作就是图2中的groupByKey和join操作。拿join操作来说,必须通过在textFile数据中和hadoopFile数据中做全量的匹配才可以得到join后的dataframe。而groupby操作需要对数据中所有相同的key进行合并,也需要全局的shuffle才能够完成。
与之相比,map,filter等操作仅需要逐条的进行数据处理和转换就可以,不需要进行数据间的操作,因此各partition之间可以并行处理。
除此之外,在得到最终的计算结果之前,程序需要进行reduce的操作,从各partition上汇总统计结果,随着partition的数量逐渐减小,reduce操作的并行程度逐渐降低,直到将最终的计算结果汇总到master节点上。
所以可以说shuffle和reduce操作的发生决定了纯并行处理阶段的边界。如图3所示,Spark的DAG被分割成了不同的并行处理阶段(stage)。
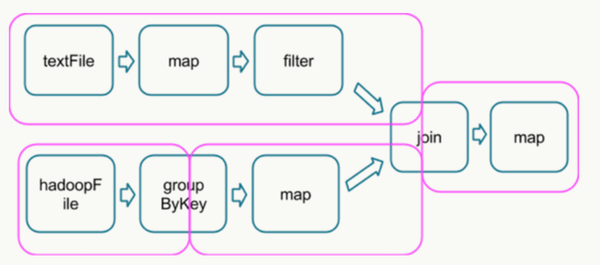

需要强调的是shuffle操作需要在不同计算节点之间进行数据交换,非常消耗计算、通信及存储资源,因此shuffle操作是spark程序应该尽量避免的。一句话总结Spark的计算过程就是:Stage内部数据高效并行计算,Stage边界处进行消耗资源的shuffle操作或者最终的reduce操作。
Spark MLlib并行训练原理
有了Spark分布式计算过程的基础,下面就可以更清楚的理解Spark MLlib并行训练的原理。
在所有主流的机器学习模型中,Random Forest的模型结构特点决定了其可以完全进行数据并行的模型训练,而GBDT的结构特点则决定了树之间只能进行串行的训练,这里就不再赘述其spark的实现方式,我们将重点放在梯度下降类方法的实现上,因为梯度下降的并行程度实现质量直接决定了以Logistic Regression为基础,以Multiple Layer Perceptron为代表的深度学习模型的训练速度。
这里,我们深入到Spark MLlib的源码中,直接把Spark做mini Batch梯度下降的源码贴出如下(代码摘自Spark 2.4.3 GradientDescent 类的 runMiniBatchSGD 函数):
while (!converged && i <= numIterations) {
val bcWeights = data.context.broadcast(weights)
// Sample a subset (fraction miniBatchFraction) of the total data
// compute and sum up the subgradients on this subset (this is one map-reduce)
val (gradientSum, lossSum, miniBatchSize) = data.sample(false, miniBatchFraction, 42 + i)
.treeAggregate((BDV.zeros[Double](n), 0.0, 0L))(
seqOp = (c, v) => {
// c: (grad, loss, count), v: (label, features)
val l = gradient.compute(v._2, v._1, bcWeights.value, Vectors.fromBreeze(c._1))
(c._1, c._2 + l, c._3 + 1)
},
combOp = (c1, c2) => {
// c: (grad, loss, count)
(c1._1 += c2._1, c1._2 + c2._2, c1._3 + c2._3)
})
bcWeights.destroy(blocking = false)
if (miniBatchSize > 0) {
/**
* lossSum is computed using the weights from the previous iteration
* and regVal is the regularization value computed in the previous iteration as well.
*/
stochasticLossHistory += lossSum / miniBatchSize + regVal
val update = updater.compute(
weights, Vectors.fromBreeze(gradientSum / miniBatchSize.toDouble),
stepSize, i, regParam)
weights = update._1
regVal = update._2
previousWeights = currentWeights
currentWeights = Some(weights)
if (previousWeights != None && currentWeights != None) {
converged = isConverged(previousWeights.get,
currentWeights.get, convergenceTol)
}
} else {
logWarning(s"Iteration ($i/$numIterations). The size of sampled batch is zero")
}
i += 1
}
乍一看比较复杂,这里可以为大家做一个精简,只列出关键的操作部分,大家就可以一目了然Spark在做什么。
while (i <= numIterations) { //迭代次数不超过上限
val bcWeights = data.context.broadcast(weights) //广播模型所有权重参数
val (gradientSum, lossSum, miniBatchSize) = data.sample(false, miniBatchFraction, 42 + i)
.treeAggregate() //各节点采样后计算梯度,通过treeAggregate汇总梯度
val weights = updater.compute(weights, gradientSum / miniBatchSize) //根据梯度更新权重
i += 1 //迭代次数+1
}经过精简的代码非常简单,Spark的mini batch过程制作了三件事:
- 把当前的模型参数广播到各个数据partition(可当作虚拟的计算节点)
- 各计算节点进行数据抽样得到mini batch的数据,分别计算梯度,再通过treeAggregate操作汇总梯度,得到最终梯度gradientSum
- 利用gradientSum更新模型权重
这样一来,每次迭代的Stage和Stage的边界就非常清楚了,Stage内部的并行部分是各节点分别采样并计算梯度的过程,Stage的边界是汇总加和各节点梯度的过程。这里再强调一下汇总梯度的操作treeAggregate,该操作是进行类似树结构的逐层汇总,整个操作流程如图4所示。
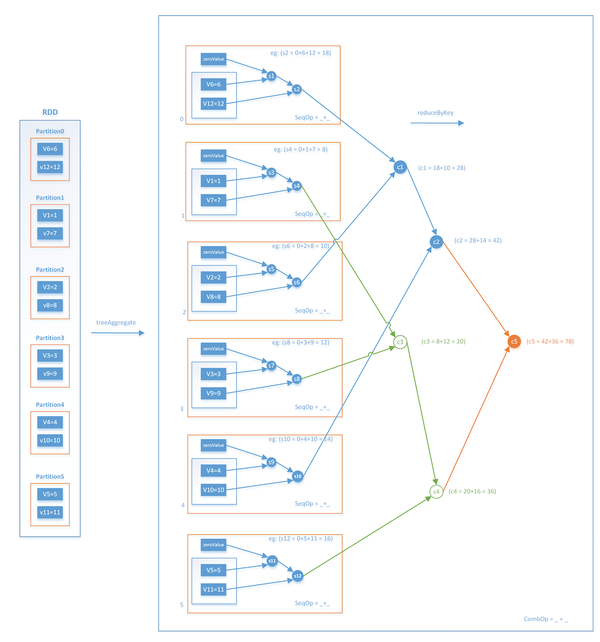
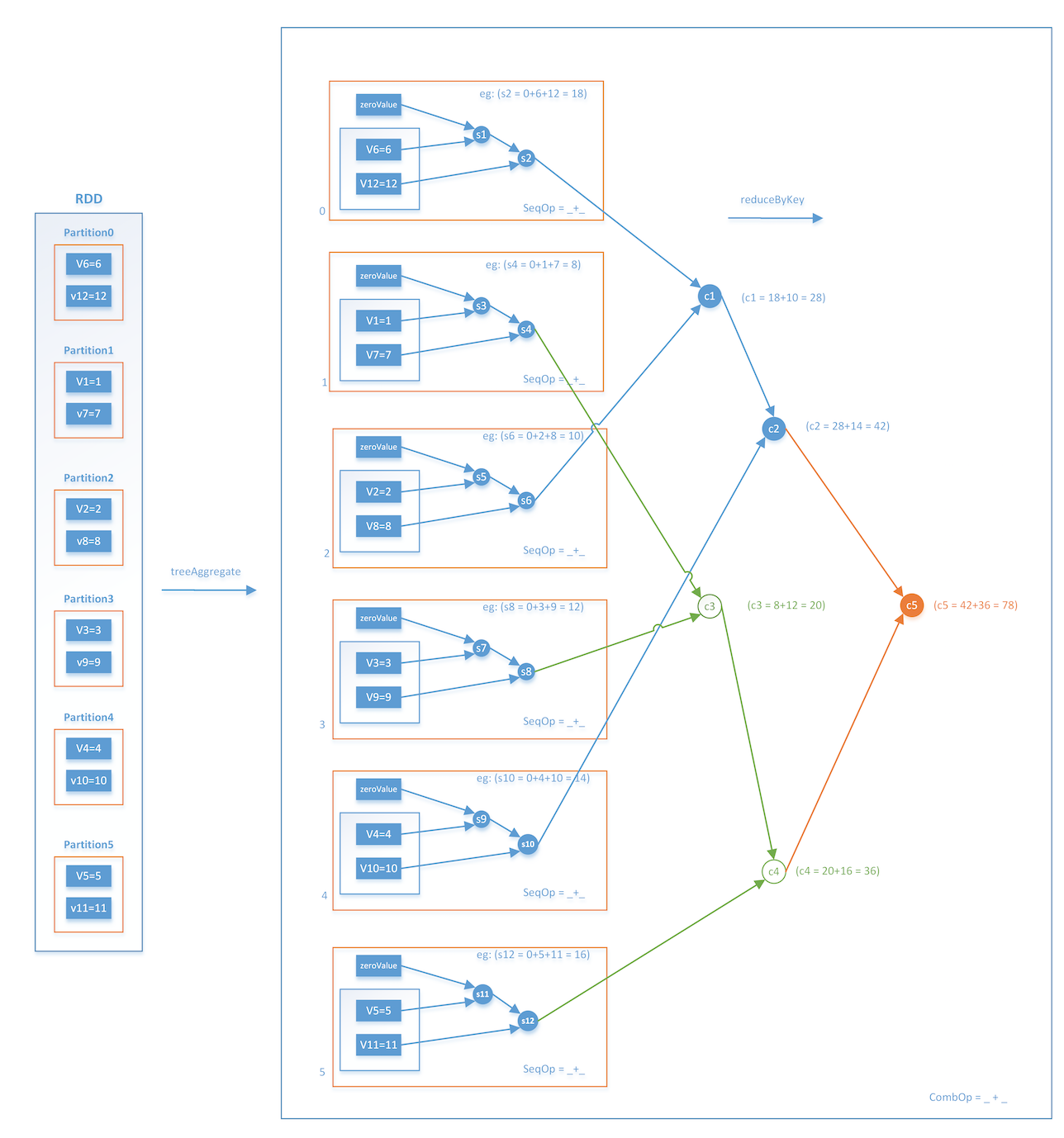
事实上,treeAggregate是一次reduce操作,本身并不包含shuffle操作,再加上采用分层的树形操作,在每层中都是并行执行的,因此整个过程是相对高效的。
在迭代次数达到上限或者模型已经充分收敛后,模型停止训练。这就是Spark MLlib进行mini batch梯度下降的全过程,也是Spark MLlib实现分布式机器学习的最典型代表。
总结来说,Spark MLlib的并行训练过程其实是“数据并行”的过程,并不涉及到过于复杂的梯度更新策略,也没有通过“参数并行”的方式实现并行训练。这样的方式简单、直观,易于实现,但也存在着一些局限性。
Spark MLlib并行训练的局限性
虽然Spark MLlib基于分布式集群,利用数据并行的方式实现了梯度下降的并行训练,但是有Spark MLlib使用经验的同学应该都清楚,使用Spark MLlib训练复杂神经网络时,往往力不从心,不仅训练时间过长,而且在模型参数过多时,经常会存在内存溢出的问题。具体来讲,Spark MLlib的分布式训练方法有下面几个弊端:
- 采用全局广播的方式,在每轮迭代前广播全部模型参数。众所周知Spark的广播过程非常消耗带宽资源,特别是当模型的参数规模过大时,广播过程和在每个节点都维护一个权重参数副本的过程都是极消耗资源的过程,这导致了Spark在面对复杂模型时的表现不佳;
- 采用阻断式的梯度下降方式,每轮梯度下降由最慢的节点决定。从上面的分析可知,Spark MLlib的mini batch的过程是在所有节点计算完各自的梯度之后,逐层Aggregate最终汇总生成全局的梯度。也就是说,如果由于数据倾斜等问题导致某个节点计算梯度的时间过长,那么这一过程将block其他所有节点无法执行新的任务。这种同步阻断的分布式梯度计算方式,是Spark MLlib并行训练效率较低的主要原因;
- Spark MLlib并不支持复杂网络结构和大量可调超参。事实上,Spark MLlib在其标准库里只支持标准的多层感知机神经网络的训练,并不支持RNN,LSTM等复杂网络结构,而且也无法选择不同的activation function等大量超参。这就导致Spark MLlib在支持深度学习方面的能力欠佳。
因为这些原因,如果想寻求更高效的训练速度和更灵活的网络结构,势必需要寻求其他平台的帮助。在这样的情势下,Parameter Server凭借其高效的分布式训练手段成为分布式机器学习的主流,而TensorFlow,PyTorch等深度学习平台则凭借灵活可调整的网络结构,完整的训练、上线支持,成为深度学习平台的主要选择。下两篇内容,本专栏将分别介绍Patameter Server和TensorFlow的并行训练原理。
例行的问题讨论时间,其他与你一起讨论和分享业界相关的经验:
- 如果希望在Spark上训练深度学习模型,你有没有改进Spark的方法?使用第三方lib?还是修改Spark源码?还是自研Spark模型?
- 在训练完成Spark模型后,应该使用什么方式将Spark模型deploy到线上环境,做线上的实时inference?
这里是 王喆的机器学习笔记 的第二十五篇文章。
认为文章有价值的同学,欢迎关注我的 微信公众号:王喆的机器学习笔记(wangzhenotes),跟踪计算广告、推荐系统等机器学习领域前沿。
想进一步交流的同学也可以通过公众号加我的微信一同探讨技术问题,谢谢。
本文亦收录在我的新书「深度学习推荐系统」中,这本书系统性地整理、介绍了专栏中所有的重点内容,如果您曾在「王喆的机器学习笔记」中受益,欢迎订阅,谢谢知友们的支持!

