
论文阅读:DenseBox

7、 Refine with Landmark Localization.
10、The Averate Presision on KITTI Car Detection Task
1、论文总述


这篇论文提出的目标检测算法与RCNN系列的路子不一样,毕竟是在Fast rcnn发表之前就已经提出的,只是发表的比较晚,一作是当时还在百度任职的黄李超大佬,现在去了地平线,因为在Faster RCNN和YOLO之后发表的,所以论文中会有与这两篇Paper 的对比。
该论文中的大部分idea都很新颖,到如今 anchor free 盛行的时代,更是又要火了一把,本论文主要是针对在人脸和车辆小目标且数量多的场景下进行目标的检测,提出了一个统一的、基于FCN的one_stage的end2end的多任务目标检测框架(在15年就做到了FCN!),并且还将landmark(关键点)引入到检测中,就更是多任务学习了,有点像maskrcnn中将目标分割也加入到模型中,这样可以进一步提高目标检测的性能,还有一点就是 正负样本的区分方式 有点像最近的anchor free 的方法,即GT为一个5层的 map,将正样本置于中心,离正样本远的为负样本(我想到了SiamFC中正负样本的区分方式。。),5层中的第一层为置信度,后面四层为距离BB四个坐标(对角,左上和右下)的距离,这样GT map的每个像素点都确定了一个框,预测的时候每个像素点也会预测一个框,有点类似yolov1的anchor free的预测框的方法,核心思想是改变了bounding box的编码方式。还有一点是为了提高小目标的召回率,conv3_4、conv4_4,在网络中引入了上采样操作,将低层和高层的特征融合以得到更大尺度的feature map输出,这也是后来的ssd 和fpn的思想,训练时候为了更好地处理困难样本,还用了类似OHEM思想的困难样例挖掘,即对loss大的样本进行筛选。
In this work, we focus on one question: To what extent can an one-stage FCN perform on object detection? To this end, we present a novel FCN based object detector, DenseBox, that does not require proposal generation and is able to be optimized end-to-end during training. Although similar to many existing sliding window fashion FCN detection frameworks [34, 8, 29], DenseBox is more
carefully designed to detect objects under small scales and heavy occlusion. We train DenseBox and apply careful hard negative mining techniques to boostrap the detection performance. To make it even better,we further integrate landmark localization into the system through joint multi-task learning [1]. To verify the usefulness of landmark localization, we manually annotate a set of keypoints for the KITTI car detection dataset [13] and will release annotation afterward.
2、 CNN之前的目标检测的相关工作
The literature on object detection is vast. Before the success of deep convolutional neural networks [18], the widely used detection systems are based on a combination of independent components. First, handcrafted image features such as HOG [5, 45, 44], SIFT [25], and Fisher Vector [4]
are extracted at every location and scale of an image. Second, object models such as pictorial structure model (PSM) [12] and deformable part-based model (DPM) [11, 46, 43] allow object parts (e.g.
head, torso, arms and legs of human) to deform with geometric constraints. Finally, a classifier such
as boosting methods [39], linear SVM [5], latent SVM [11], or random forests [7] decides whether
a candidate window shall be detected as containing an object.(主要就是划框的方式用人工设计的特征,然后加一个svm类似的分类器)
3、DenseBox In the test
All components of object detection
in DenseBox are modeled as a fully convolutional network except the non-maximum suppression
step, so region proposal generation is unnecessary. In the test, the system takes an image (at the
size of m × n) as input, and output a m/4 × n/4
feature map with 5 channels. If we define the left
top and right bottom points of the target bounding box in output coordinate space as pt = (xt, yt)
and as pb = (xb, yb) respectively, then each pixel i located at (xi
, yi) in the output feature map
describe a bounding box with a 5-dimensional vector tˆi = {s, ˆ ˆ dxt = xi i xt,,
ˆdyt = yi iyt, ˆdxb = xi i xb, ˆdyb = yi i yb}i
, where sˆ is the confidence score of being an object and ˆdxt, ˆdyt, ˆdxb, ˆdyb denote the distance between output pixel location with the boundary of target bounding box.
Finally every pixel in the output map is converted to bounding box with score, and non-maximum
suppression is applied to those boxes whose scores pass the threshold.
就是除了nms外,整个网络是一个FCN,因为是全卷积网络,最后在输出的(m / 4) x (n / 4) x 5通道的feature map上,根据5-d向量可以得到海量bbox坐标 + 置信度得分,在经过NMS过滤 + 阈值过滤求得最终检测框。
4、Ground Truth Generation


样本的标GT也与众不同,并没有用IOU大于多少便是正样本的这种方式,作者认为把整张图都放进网络意义不大,因为背景太多,所以就crop,让某个人脸处于image的正中心,并且有足够的背景信息,然后将image resize成 240*240 之后使得人脸的高度为50个像素,这样crop的时候就知道该crop多大了。
然后这样的还不是GT map,这个网络训练和测试的时候的downsampling factor都是4,所以 GT map是60 * 60 * 5的5维的map ,和网络输出的feature map类似,但这个GT map应该是作者构建的,但feature map是需要训练生成的。在 60 * 60 * 5的GT map的第一层上,位于中心点附近rc半径内的都是正样本,rc为BB size的0.3.即这圆内的像素标签都标注为1,后面的四个channel为四个坐标,距离BB的左上和右下坐标的距离。
有需要注意的点:
Note that if multiple faces occur in one patch, we keep those faces as positive if they fall in a scale (????不理解这个骚操作,不知道是在干啥)
range(e.g. 0.8 to 1.25 in our setting) relative to the face in patch center. Other faces are treated as
negative samples. The pixels of first channel, which denote the confidence score of class, in the
ground truth map are initialized with 0, and further set to 1 if within the positive label region. We
also find our ground truth generation is quite similar to the segmentation work[28] by Pinheiro et.al. (这种GT标注方式和分割网络的很像,但也有不同,因为DenseBox用的是感受野!!)
In their method, the pixel label is decided by the location of object in patch, while in DenseBox, the
pixel label is determined by the receptive field. Specifically, if the output pixel is labeled to 1 if it
satisfies the constraint that its receptive field contains an object roughly in the center and in a given
scale. Each pixel can be treated as one sample , since every 5-channel pixel describe a bounding box.
maybe :就是说一个patch里可能包含多个人脸,如果那个人脸的中心位于patch中心的一定的尺度范围内,则也将它作为正样本,那这个的rc周围也是正样本了,相当于rc变大了。
关于感受野和GT的关系:
简单点说就是被检测图像要过DenseBox网络,经过若干层卷积得到feature map后,我们得到的该feature map上每个像素的感受野大于50 x 50,我们已知gt bbox的尺度为50 x 50,那么这个感受野就包含了人脸bbox,也就是上面一段:its receptive field contains an object roughly in the center,240 x 240就是:in a given scale;也就是说其实输入的图像patch尺度240 x 240,人脸尺度gt bbox都是和DenseBox本身网络结构有关的,经过若干层卷积后,要保证用于预测人脸的feature map上感受野要包含人脸的50 x 50尺度,不然预测是没有意义的;
5、Multi-Level Feature Fusion
Recent works[2, 22] indicate that using features from different convolution layers can enhance performance in task such as edge detection and segmentation. Part-level
feature focus on local details of object to find discriminative appearance parts, while object-level or
high-level feature usually has a larger receptive field in order to recognize object. The larger receptive field also brings in context information to predict more accurate result. In our implementation,
we concatenate feature map from conv3 4 and conv4 4. The receptive field (or sliding window size)
of conv3 4 is 48×48, almost the same size of the face size in training, and the conv4 4 have a much
larger receptive field, around 118 × 118 in size, which could utilize global textures and context for
detection. Note that the feature map size of conv4 4 is half of the map generated by conv3 4, hence
we use a bilinear up-sampling layer to transform them to the same resolution.
融合了 conv3_4 和 conv4_4 的特征,低级特征对细节把握的较好,而高级特征则对识别目标能力比较强,语义信息级别更高。
6、Loss with Mask.
训练时用到了类似OHEM的方法,还有一个灰色地带,即正样本周围的2个像素的样本为灰色地带,既不是正样本也不是负样本,因为会降低模型的性能。


7、 Refine with Landmark Localization.
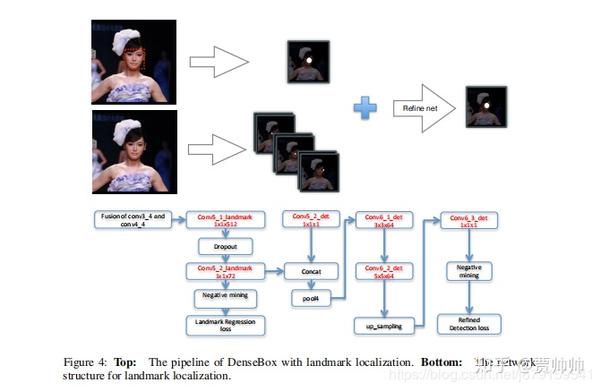

DenseBox中增加landmark定位分支(通过增加若干全卷积分支实现),以提升目标检测准确度的工作,并可以联合landmark热度图和人脸得分热度图进一步提升目标检测精准度;
fig4中,为landmark定位新增了一个分支,如果要输出N个landmark,那么landmark定位分支共输出N通道的feature map,feature map上每个像素表示该位置为一个特定landmark的概率(each pixel represent the confidence score of being a landmark at that location);从这点上来看,landmark分支的gt feature map和检测分支的gt feature map是非常相似的,二者的区别在于:检测分支的gt feature map是四通道,landmark分支的gt feature map是N通道,N对应要输出的landmark数目;---- 有多少landmark点,就输出多少通道即可。(人脸是72个关键点,而车辆是作者自己标注的8个关键点)。
其中关键点的损失函数为
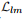
和检测中的分裂损失类似,但是论文中还有一个损失,
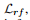
这个损失根据上图可以看出来,是在加入了landmark之后,联合两个结构进行进一步的refine,
The final output refine branch, taking the classification score map and landmark localization maps
as input, targets on refine of the detection results. An appropriate solution could be using highlevel spatial model to learn the constraints of landmark confidence and bounding box score, to further increase the performance of detections.
最终损失为:
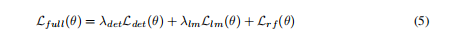

注意:这是4个子任务
8、与其他网络的比较
OverFeat:OverFeat对分类和定位不能联合训练
Deep Dense Face Detector (DDFD):不是end to end的框架
Faster R-CNN:需要rpn来产生 proposals,是有anchor的,而densebox无anchor
MultiBox:MultiBox产生的proposals没有平移不变性,而densebox的有
YOLO:yolo只有7*7的grid cell产生proposals比较少,而且没有up-sampling,对小目标检测效果不好
9、关键点示意


10、The Averate Presision on KITTI Car Detection Task
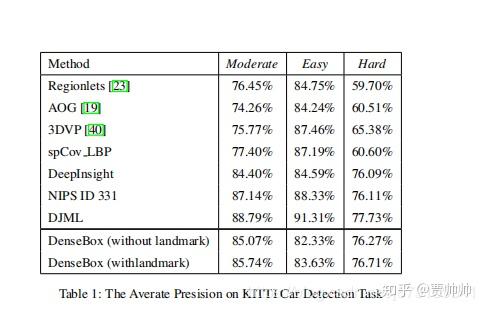

DenseBox在 KITTI car detection set是霸榜了四个月的,后来被NIPS
ID 331超越了,
which use stereo information for training and testing. (用了立体信息)
Recently a method named “DJML
overtakes all other methods.
