tensorflow optimizer源码阅读笔记


一直对tf中的自动求导机制比较好奇,它内部到底是怎么做梯度的反向传播的呢?所以最近阅读了tensorflow/python/training/optimizer.py的源码。其实tf的自动求导就是靠各式各样的Optimizer类进行的,我们只需要在程序中构建前向图,然后加上Optimizer,再调用minimize()方法就可以完成梯度的反向传播。
Optimizer class是所有Optimizer的基类(比如GradientDescentOptimizer、AdamOptimizer等),整个反向传播过程可分为三步,这三步仅需通过一个minimize()函数完成:
- 计算每一个部分的梯度,
compute_gradients() - 根据需要对梯度进行处理
- 把梯度更新到参数上,
apply_gradients()
compute_gradients函数
参数gate_gradients:用于控制梯度计算过程的并行性
GATE_GRAPH 很好理解,即整个图中间的梯度计算(后向过程)和梯度更新是单独分开的,计算过程严格按照前向、后向、更新的步骤来,等到所有的参数都完成梯度计算之后,再统一发起更新。
GATE_NONE 和 GATE_OP 的差别在于梯度更新会不会影响到后续的其他计算。例如某个 op 有 n 个输入 x0,x1,…,xn−1,梯度的计算和更新需要对所有这 n 个输入求导,在 GATE_NONE 模式下,x0的梯度计算完了之后,对 x0 的更新就马上开始了,那么在算其他输入(例如 xn−1)的梯度时,如果梯度项中含有x0,就可能会出现“不可复现”的结果,因为每次算梯度时不一定哪一个梯度先算完呢。
GATE_OP 即产生一些控制依赖,确定某个变量不再会被用到之后才进行更新,保证正确性的同时最大化并行性。
核心代码:
if var_list is None:
var_list = (
variables.trainable_variables() +
ops.get_collection(ops.GraphKeys.TRAINABLE_RESOURCE_VARIABLES))
else:
var_list = nest.flatten(var_list)
# pylint: disable=protected-access
var_list += ops.get_collection(ops.GraphKeys._STREAMING_MODEL_PORTS)
# pylint: enable=protected-access
processors = [_get_processor(v) for v in var_list]
if not var_list:
raise ValueError("No variables to optimize.")
var_refs = [p.target() for p in processors]
grads = gradients.gradients(
loss, var_refs, grad_ys=grad_loss,
gate_gradients=(gate_gradients == Optimizer.GATE_OP),
aggregation_method=aggregation_method,
colocate_gradients_with_ops=colocate_gradients_with_ops)
if gate_gradients == Optimizer.GATE_GRAPH:
grads = control_flow_ops.tuple(grads)
grads_and_vars = list(zip(grads, var_list))
self._assert_valid_dtypes(
[v for g, v in grads_and_vars
if g is not None and v.dtype != dtypes.resource])
return grads_and_vars其中最核心的gradients.gradients函数,该函数可执行的功能为:根据原本计算图中所有的 op创建一个顺序的list,然后反向遍历这个list,对每个需要求导并且能够求导的op(即已经定义好了对应的梯度函数的op)调用其梯度函数,然后沿着原本计算图的方向反向串起另一部分的计算图(输入输出互换,原本的数据 Tensor 换成梯度 Tensor)。
另外_get_processor函数可理解为一种快速更新variables的方法,每个processor都会包含一个update_op这样的函数来进行variable更新操作。
apply_gradients函数
apply_gradients函数根据前面求得的梯度,把梯度更新到参数上。
核心代码:
converted_grads_and_vars = tuple(converted_grads_and_vars)
var_list = [v for g, v, _ in converted_grads_and_vars if g is not None]
if not var_list:
raise ValueError("No gradients provided for any variable: %s." %
([str(v) for _, v, _ in converted_grads_and_vars],))
with ops.init_scope():
self._create_slots(var_list)
update_ops = []
with ops.name_scope(name, self._name) as name:
self._prepare()
for grad, var, processor in converted_grads_and_vars:
if grad is None:
continue
# We colocate all ops created in _apply_dense or _apply_sparse
# on the same device as the variable.
# TODO(apassos): figure out how to get the variable name here.
if (context.executing_eagerly() or
resource_variable_ops.is_resource_variable(var)
and not var._in_graph_mode): # pylint: disable=protected-access
scope_name = ""
else:
scope_name = var.op.name
with ops.name_scope("update_" + scope_name), ops.colocate_with(var):
update_ops.append(processor.update_op(self, grad))
if global_step is None:
apply_updates = self._finish(update_ops, name)
else:
with ops.control_dependencies([self._finish(update_ops, "update")]):
with ops.colocate_with(global_step):
if isinstance(
global_step, resource_variable_ops.BaseResourceVariable):
# TODO(apassos): the implicit read in assign_add is slow; consider
# making it less so.
apply_updates = resource_variable_ops.assign_add_variable_op(
global_step.handle,
ops.convert_to_tensor(1, dtype=global_step.dtype),
name=name)
else:
apply_updates = state_ops.assign_add(global_step, 1, name=name)
if not context.executing_eagerly():
if isinstance(apply_updates, ops.Tensor):
apply_updates = apply_updates.op
train_op = ops.get_collection_ref(ops.GraphKeys.TRAIN_OP)
if apply_updates not in train_op:
train_op.append(apply_updates)
return apply_updates其中self._create_slots函数表示创建一些优化器自带的一些参数,比如AdamOptimizer的m和v,\beta_1的t次方(beta1_power)和\beta_2的t次方(beta2_power)。prepare()函数的作用是在apply梯度前创建好所有必须的tensors。
ops.colocate_with(var)函数的作用是保证每个参数var的更新都在同一个device上。具体用法可以草考:https://stackoverflow.com/questions/45341067/what-is-colocate-with-used-for-in-tensorflow
ops.control_dependencies()函数用来控制计算流图的,给图中的某些节点指定计算的顺序。代码中的意思就是先执行update_ops操作,然后再执行global_step的加1操作。
Optimizer 基类的这个方法为每个实现子类预留了_create_slots(),_prepare(),_apply_dense(),_apply_sparse()四个接口出来,后面新构建的 Optimizer 只需要重写或者扩展 Optimizer 类的某几个函数即可。
apply_gradients()核心的部分就是对每个 variable 本身应用 assign,体现在update_ops.append(processor.update_op(self, grad)),如果有global_step的话,global_step需加个1。
AdamOptimizer类
首先介绍一下Adam优化器的公式:


def __init__(self,
learning_rate=0.001,
beta1=0.9,
beta2=0.999,
epsilon=1e-8,
use_locking=False,
name="Adam"):
super(AdamOptimizer, self).__init__(use_locking, name)
self._lr = learning_rate
self._beta1 = beta1
self._beta2 = beta2
self._epsilon = epsilon
# Tensor versions of the constructor arguments, created in _prepare().
self._lr_t = None
self._beta1_t = None
self._beta2_t = None
self._epsilon_t = None
def _prepare(self):
lr = self._call_if_callable(self._lr)
beta1 = self._call_if_callable(self._beta1)
beta2 = self._call_if_callable(self._beta2)
epsilon = self._call_if_callable(self._epsilon)
self._lr_t = ops.convert_to_tensor(lr, name="learning_rate")
self._beta1_t = ops.convert_to_tensor(beta1, name="beta1")
self._beta2_t = ops.convert_to_tensor(beta2, name="beta2")
self._epsilon_t = ops.convert_to_tensor(epsilon, name="epsilon")上边_init_函数可以看到,除了初始化时传进去的参数,优化器自身还存储了这些参数的 Tensor 版本,这些转换是在_prepare函数中通过convert_to_tensor方法来实现的。
def _get_beta_accumulators(self):
with ops.init_scope():
if context.executing_eagerly():
graph = None
else:
graph = ops.get_default_graph()
return (self._get_non_slot_variable("beta1_power", graph=graph),
self._get_non_slot_variable("beta2_power", graph=graph))
def _create_slots(self, var_list):
# Create the beta1 and beta2 accumulators on the same device as the first
# variable. Sort the var_list to make sure this device is consistent across
# workers (these need to go on the same PS, otherwise some updates are
# silently ignored).
first_var = min(var_list, key=lambda x: x.name)
self._create_non_slot_variable(
initial_value=self._beta1, name="beta1_power", colocate_with=first_var)
self._create_non_slot_variable(
initial_value=self._beta2, name="beta2_power", colocate_with=first_var)
# Create slots for the first and second moments.
for v in var_list:
self._zeros_slot(v, "m", self._name)
self._zeros_slot(v, "v", self._name)_create_slots函数用来创建参数,被创建的参数有m、v、\beta_1的t次方(beta1_power)和\beta_2的t次方(beta2_power)。_get_beta_accumulators函数是用来获取\beta_1的t次方(beta1_power)和\beta_2的t次方(beta2_power)的值。
def _apply_dense(self, grad, var):
m = self.get_slot(var, "m")
v = self.get_slot(var, "v")
beta1_power, beta2_power = self._get_beta_accumulators()
return training_ops.apply_adam(
var,
m,
v,
math_ops.cast(beta1_power, var.dtype.base_dtype),
math_ops.cast(beta2_power, var.dtype.base_dtype),
math_ops.cast(self._lr_t, var.dtype.base_dtype),
math_ops.cast(self._beta1_t, var.dtype.base_dtype),
math_ops.cast(self._beta2_t, var.dtype.base_dtype),
math_ops.cast(self._epsilon_t, var.dtype.base_dtype),
grad,
use_locking=self._use_locking).op
def _resource_apply_dense(self, grad, var):
m = self.get_slot(var, "m")
v = self.get_slot(var, "v")
beta1_power, beta2_power = self._get_beta_accumulators()
return training_ops.resource_apply_adam(
var.handle,
m.handle,
v.handle,
math_ops.cast(beta1_power, grad.dtype.base_dtype),
math_ops.cast(beta2_power, grad.dtype.base_dtype),
math_ops.cast(self._lr_t, grad.dtype.base_dtype),
math_ops.cast(self._beta1_t, grad.dtype.base_dtype),
math_ops.cast(self._beta2_t, grad.dtype.base_dtype),
math_ops.cast(self._epsilon_t, grad.dtype.base_dtype),
grad,
use_locking=self._use_locking)函数_apply_dense和_resource_apply_dense的实现中分别使用了training_ops.apply_adam和training_ops.resource_apply_adam方法。具体实现于:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/training_ops.cc
template <typename Device, typename T>
struct ApplyAdamNonCuda {
void operator()(const Device& d, typename TTypes<T>::Flat var,
typename TTypes<T>::Flat m, typename TTypes<T>::Flat v,
typename TTypes<T>::ConstScalar beta1_power,
typename TTypes<T>::ConstScalar beta2_power,
typename TTypes<T>::ConstScalar lr,
typename TTypes<T>::ConstScalar beta1,
typename TTypes<T>::ConstScalar beta2,
typename TTypes<T>::ConstScalar epsilon,
typename TTypes<T>::ConstFlat grad, bool use_nesterov) {
// ...
T* var_ptr = var.data();
T* m_ptr = m.data();
T* v_ptr = v.data();
const T* g_ptr = grad.data();
const T alpha = lr() * Eigen::numext::sqrt(T(1) - beta2_power()) /
(T(1) - beta1_power());
if (use_nesterov) {
m += (g - m) * (T(1) - beta1());
v += (g.square() - v) * (T(1) - beta2());
var -= ((g * (T(1) - beta1()) + beta1() * m) * alpha) /
(v.sqrt() + epsilon());
} else {
m += (g - m) * (T(1) - beta1());
v += (g.square() - v) * (T(1) - beta2());
var -= (m * alpha) / (v.sqrt() + epsilon());
}
// ...
}
};
在上面的实现中,m和v的更新公式和论文的形式上好像有些不同,但其实是一样的:
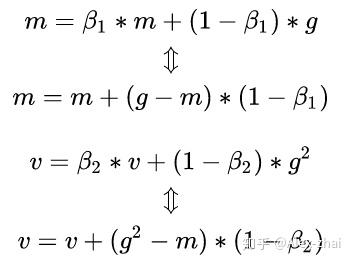
def _apply_sparse(self, grad, var):
return self._apply_sparse_shared(grad.values, var, grad.indices,
lambda x, i, v: state_ops.scatter_add(x, i, v, use_locking=self._use_locking))
def _resource_apply_sparse(self, grad, var, indices):
return self._apply_sparse_shared(grad, var, indices, self._resource_scatter_add)
def _resource_scatter_add(self, x, i, v):
with ops.control_dependencies([resource_variable_ops.resource_scatter_add(x.handle, i, v)]):
return x.value()函数_apply_sparse和_resource_apply_sparse主要用在稀疏向量的更新操作上,而具体的实现是在函数_apply_sparse_shared中。
def _apply_sparse_shared(self, grad, var, indices, scatter_add):
beta1_power, beta2_power = self._get_beta_accumulators()
beta1_power = math_ops.cast(beta1_power, var.dtype.base_dtype)
beta2_power = math_ops.cast(beta2_power, var.dtype.base_dtype)
lr_t = math_ops.cast(self._lr_t, var.dtype.base_dtype)
beta1_t = math_ops.cast(self._beta1_t, var.dtype.base_dtype)
beta2_t = math_ops.cast(self._beta2_t, var.dtype.base_dtype)
epsilon_t = math_ops.cast(self._epsilon_t, var.dtype.base_dtype)
lr = (lr_t * math_ops.sqrt(1 - beta2_power) / (1 - beta1_power))
# m_t = beta1 * m + (1 - beta1) * g_t
m = self.get_slot(var, "m")
m_scaled_g_values = grad * (1 - beta1_t)
m_t = state_ops.assign(m, m * beta1_t, use_locking=self._use_locking)
with ops.control_dependencies([m_t]):
m_t = scatter_add(m, indices, m_scaled_g_values)
# v_t = beta2 * v + (1 - beta2) * (g_t * g_t)
v = self.get_slot(var, "v")
v_scaled_g_values = (grad * grad) * (1 - beta2_t)
v_t = state_ops.assign(v, v * beta2_t, use_locking=self._use_locking)
with ops.control_dependencies([v_t]):
v_t = scatter_add(v, indices, v_scaled_g_values)
v_sqrt = math_ops.sqrt(v_t)
var_update = state_ops.assign_sub(
var, lr * m_t / (v_sqrt + epsilon_t), use_locking=self._use_locking)
return control_flow_ops.group(*[var_update, m_t, v_t])scatter_add函数作用是完成稀疏Tensor的加操作,其中代码中的参数m相当于ref,indices是索引,m_scaled_g_values是更新的值。
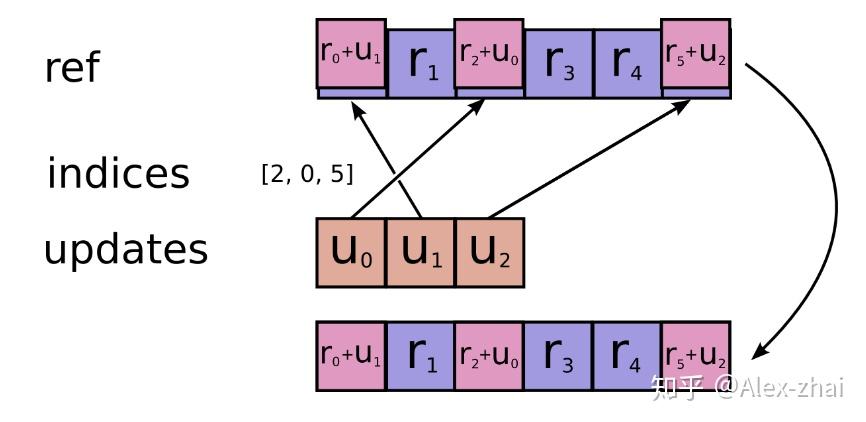
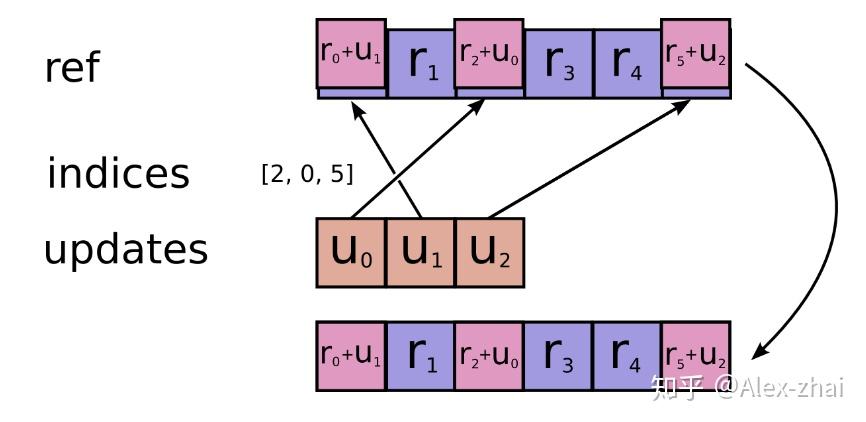
那么现在分析下_apply_sparse_shared函数,首先获取所需要的参数值并存储到变量里,接着按照 Adam 算法的流程,首先计算学习率\alpha_t,接着计算两个 Momentum ,由于是稀疏 tensor 的更新,所以在算出更新值之后要使用scatter_add来完成加法操作, 最后将var_update和m_t、v_t的更新操作放进control_flow_ops.group中。
def _finish(self, update_ops, name_scope):
# Update the power accumulators.
with ops.control_dependencies(update_ops):
beta1_power, beta2_power = self._get_beta_accumulators()
with ops.colocate_with(beta1_power):
update_beta1 = beta1_power.assign(
beta1_power * self._beta1_t, use_locking=self._use_locking)
update_beta2 = beta2_power.assign(
beta2_power * self._beta2_t, use_locking=self._use_locking)
return control_flow_ops.group(
*update_ops + [update_beta1, update_beta2], name=name_scope)\beta_1的t次方(beta1_power)和\beta_2的t次方(beta2_power)是在通过_finish函数计算的,通过之前存储的\beta_1^{t-1} * \beta_1和\beta_2^{t-1} * \beta_2的更新op,并将这两个更新操作放进放到control_flow_ops.group中。 可以发现adam 算法的所有的更新计算操作都会放进control_flow_ops.group中。
参考文献:
- http://jcf94.com/2018/01/23/2018-01-23-tfunpacking2/
- https://zhuanlan.zhihu.com/p/40870669
- https://zhuanlan.zhihu.com/p/63500952
- https://github.com/tensorflow/tensorflow/blob/818704e5cad0bed56f14281e9105eb39c1060bd1/tensorflow/python/training/optimizer.py
- https://github.com/tensorflow/tensorflow/blob/818704e5cad0bed56f14281e9105eb39c1060bd1/tensorflow/python/training/adam.py#L145
