推荐系统简明教程-排序

本文为《推荐系统简明教程》的第三篇,为便于全面了解推荐系统,推荐阅读前两篇内容
检索
假设已经有了一个Embedding模型。 给定用户,该如何决定推荐哪些item呢?
在服务时,给定查询,首先要执行以下操作之一:
- 对于矩阵分解模型,query(或user)Embedding是静态已知的,并且系统可以简单地从Embedding矩阵中查找到。
- 对于DNN模型,系统将在服务时间内计算特征向量 x 通过网络后对应的Embedding \psi(x) 。
有了query Embedding q 后,在Embedding空间中搜索最接近 q 的item Embedding V_j 。 这是一个最近邻问题。 例如,可以根据相似度 s(q,V_j) 得分返回前k个item。

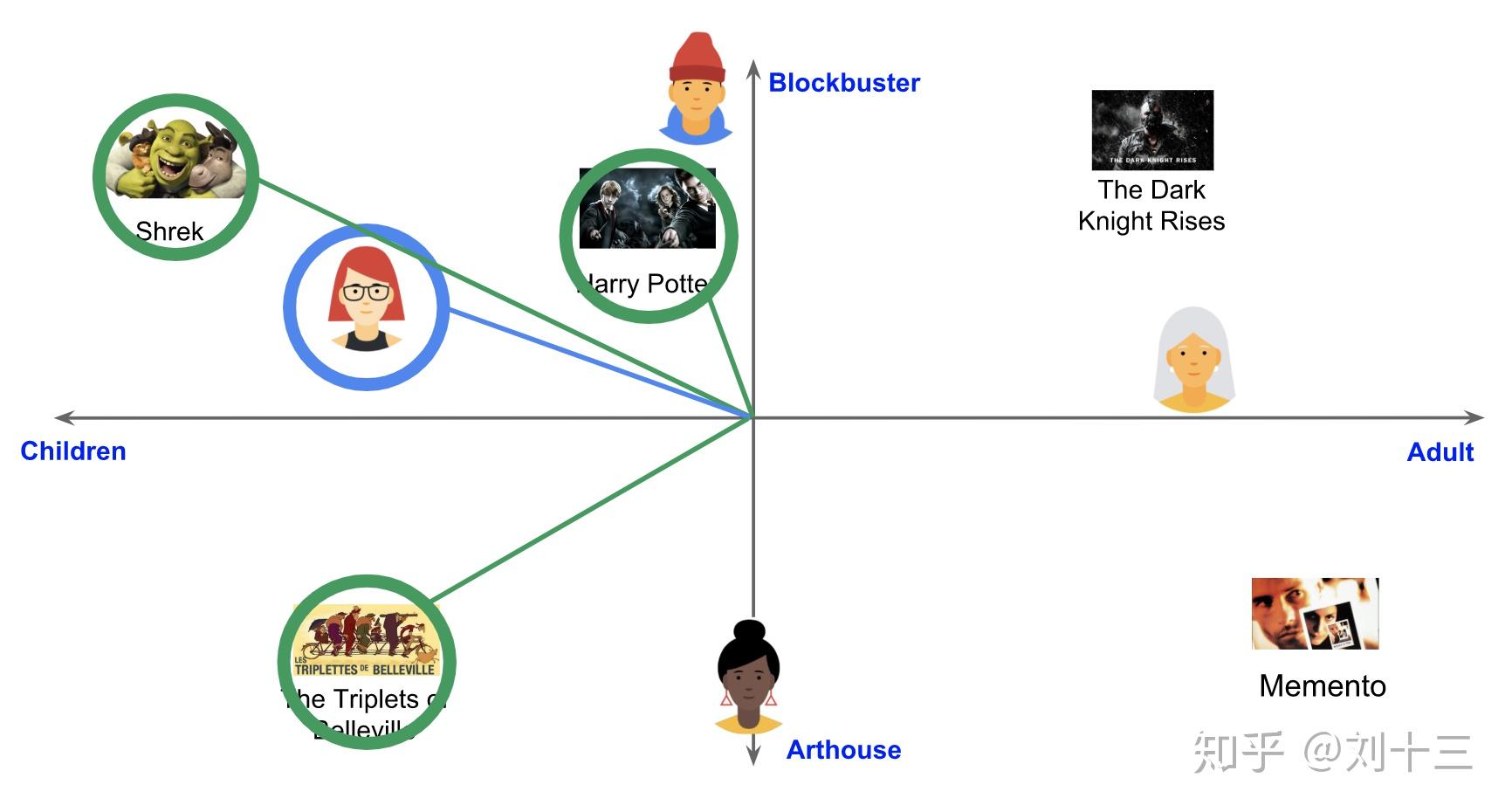
该方法同样可以用于相关item推荐。 例如,当用户观看视频时,系统可以先查找该item对应的Embedding,然后在Embedding空间中查找距离最近的item V_j 。
大规模检索
为了计算Embedding空间中最接近的top-K个item,系统可以详尽地对计算每个潜在候选者的评分。 但对于大的语料库,详尽的评分可能会很耗时,可以使用以下两种策略之一来提高其效率:
- 如果query Embedding是静态已知的,则系统可以脱机计算详尽的评分,预先计算并存储每个query的最佳候选item列表。 这是相关item推荐的常见做法。
- 使用近似最近邻。
排序
在生成候选对象之后,另一个模型会对生成的候选对象进行打分和排序,得到最后要推送的item列表。 推荐系统可能具有使用不同来源的多个召回队列,例如:
- 矩阵分解模型的相关item。
- 个性化的用户item。
- “本地”与“非本地”项目; 也就是说,要考虑地理信息。
- 热门或流行item。
- 社交网络; 也就是朋友喜欢或推荐的item。
系统将这些不同的来源组合成一个通用的候选库,然后由单个模型对其进行打分并根据该分数进行排名。 例如,系统可以根据以下特征训练模型以预测用户观看视频的概率:
- 查询特征(例如,用户观看记录,语言,国家/地区,时间)
- 视频特征(例如标题,标签,视频Embedding)
然后,系统可以根据模型的预测对候选库中的视频进行排序。
为什么不使用召回阶段的得分进行排序,而要重新计算分数?
由于召回阶段会计算分数(例如Embedding空间中的相似性得分),因此您可能会尝试使用此得分进行排序。 但是,出于以下原因,应避免这种做法:
- 一些系统依赖多个召回队列。 这些不同召回队列的得分不具有可比性。
- 由于候选池较小,因此系统可以负担得起更多特征和更复杂的精排模型(可以更好地捕获上下文)。
选择排序模型的目标函数
目标函数的选择会极大地影响item的排序结果,并最终影响推荐的质量。
常用的优化目标有以下几种:
最大化点击率:如果目标函数只针对点击进行优化,则系统可能会推荐诱导用户点击的视频。 该目标函数可以提高用户点击,但不能带来良好的用户体验。 用户的兴趣可能会很快消失。
延长观看时间:如果目标函数针对观看时间进行优化,则系统可能会推荐较长的视频,这可能会导致不良的用户体验。 多个短视频的观看时长和一个长视频的观看时长一样是一样的。
增加多样性并最大化观看时间:推荐较短的,但更可能吸引用户的视频。
打分的位置偏差
与在屏幕上方显示的item相比,在屏幕下方显示的item被点击的可能性较小。 但是,在对视频打分时,系统通常不知道最终将显示该视频的链接在屏幕上的哪个位置。 对所有可能的位置进行打分太耗时了。 即使对多个位置打分是可行的,系统仍可能无法在多个排序得分中保持一致性。
解决方案
- 创建与位置无关的排序。
- 对所有候选item进行排序,假设他们都在屏幕的顶部。
针对位置偏差也可使用相应的点击模型对排序结果进行调权纠正,详细的点击模型可查看下文:
重排
在推荐系统的最后阶段,系统对候选item重新排序,以考虑其他因素或约束。 一种重新排序的方法是使用过滤器来删除一些候选item。
示例:可以通过执行以下操作来对视频推荐结果进行重新排名:
- 训练一个单独的模型来检测视频是否为诱惑点击的钓鱼视频。
- 在候选集上运行此模型。
- 在候选集中删除模型判断结果为诱惑点击的视频。
另一种重排方法是转换排序阶段返回的分数。
示例:系统根据以下函数修改得分来重新对视频进行排序:
- 影片出品时间(也许是在宣传新内容)
- 影片长度
下面简单介绍下时效性,多样性和公平性。 这些都是可以帮助改善推荐系统的重要因素。 其中一些因素通常需要修改流程的不同阶段。 每个部分均提供您可以单独或共同应用的解决方案。
时效性
大多数推荐系统旨在融合最新的使用信息,例如当前用户历史记录和最新item。使模型保持最新状态有助于模型给出更好的推荐。
解决方案:
- 尽可能频繁地重新训练模型以学习最新的训练数据。建议使用在线学习或增量学习等相关技术,以便模型不必从头开始重新学习。增量学习可以大大减少训练时间。例如,在矩阵分解中,加载先前计算出的item Embedding进行更新计算。
- 创建一个“平均”用户来代表矩阵分解模型中的新用户。不需要为每个用户使用相同的Embedding,可以根据用户特征对用户进行聚类。
- 使用诸如DNN模型或双塔模型。由于该模型将特征向量作为输入,因此可以在执行在训练数据中未出现的query或item。
- 添加item年龄相关信息作为特征。例如,可以将视频发布了多长时间或上次观看的时间添加为特征。
多样性
如果系统始终推荐与query Embedding “最接近”的item,则候选item往往彼此非常相似。 多样性的缺乏会导致无聊的用户体验。 例如,如果仅推荐与用户当前正在观看的视频非常相似的视频,那么用户可能会很快失去兴趣。
解决方案
- 使用不同的来源训练多个召回队列。
- 使用不同的目标函数训练多个排序模型。
- 根据类别或其他元数据对item重新排序,以确保多样性。
公平性
模型应公平对待所有用户。 因此,请确保模型没有从训练数据中学习到无意识的偏见。
解决方案
- 在设计和开发中融入不同的角度。
- 在综合数据集上训练ML模型。 当数据太稀疏时(例如,某些类别的代表性不足时),添加辅助数据。
- 跟踪每个用户统计指标(例如,准确性和绝对误差)以观察偏差。
- 为特定群体训练单独的模型。
