
动态 Probit 模型及 Stata 实现

作者:万源星 (浙江工商大学财务与会计学院)
Stata 连享会:(知乎 | 简书 | 码云 | CSDN | 公众号 StataChina)
连享会 最新专题 直播


连享会-知乎推文列表
Note: 助教招聘信息请进入「课程主页」查看。
因果推断-内生性 专题 ⌚ 2020.11.12-15
主讲:王存同 (中央财经大学);司继春(上海对外经贸大学)
课程主页:https://gitee.com/arlionn/YG | 微信版
http://qr32.cn/BlTL43 (二维码自动识别)
空间计量 专题 ⌚ 2020.12.10-13
主讲:杨海生 (中山大学);范巧 (兰州大学)
课程主页:https://gitee.com/arlionn/SP | 微信版
https://gitee.com/arlionn/DSGE (二维码自动识别)
本文介绍动态面板 Porbit 模型 (Dynamic Probit Model) 的背景、模型及 Stata 应用。
1. 背景简介
动态面板数据的一般形式为:
y_{it} = \alpha_{i} + \phi y_{it-1} + \beta x_{it} + \varepsilon_{it}
模型将 y_{it-1} (可以推广到多阶滞后项) 作为解释变量,体现了被解释变量动态变化特征的模型。然而, y_{it-1} 与随机干扰项 \varepsilon_{it} 具有很强的相关性,这违背了解释变量与随机干扰项不相关的基本假设,即存在内生性问题。基于此,Arellano and Bond (1991) 提出了一阶差分广义矩 (First-difference GMM) 估计法,先通过一阶差分消除个体效应,再用被解释变量的水平值作为工具变量,降低了模型的内生性。Arellano and Bover (1995) 、Blundell and Bond (1998) 在此基础上进一步提出了系统广义矩 (System GMM) ,将被解释变量的差分值作为工具变量,减少了一阶差分广义矩估计法的偏误。
然而,Probit、Logit 等非线性模型的被解释变量是二元变量 (Binary) 或取值有限的离散变量 (Dichotomous) ,模型用极大似然法进行估计,一阶差分广义矩估计法和系统广义矩估计法难以适用。由此,本文引入动态面板 Porbit 模型 (Dynamic Probit Model) ,下文重点介绍模型的推导过程和 Stata 应用。
2. 动态 Probit 模型简介
2.1 模型设定
假设研究个体行为 (比如上市公司研发) y_{it} ,即个体 i 在第 t 年是否执行该行为,它与上一年该行为 y_{it-1} ,以及各种决定因素相关,那么动态面板 Probit 模型可以设定为:
y_{it}^{*} = c_{i} + \beta y_{it-1} + \rho x_{it} + \gamma z_{it} + \varepsilon_{it} \tag{1}
其中,y_{it}^{*} 和 y_{it} 的关系为: y_{it}^{*} 大于临界值 0 时, y_{it}=1 ,小于等于 0 时, y_{it}=0 ; c_{i} 是不可观测的个体效应; x_{it} 、 z_{it} 为解释变量,前者随时间变化而发生改变,后者则不具备动态变化特征; \varepsilon_{it} 是随机干扰项,这里假设 x_{it} 、 z_{it} 与 \varepsilon_{it} 不相关,即严格外生性。
同时,根据 Wooldridge (2005)、Skrondal and Rabe-Hesketh (2014)、Grotti and Cutuli (2018) 的概念及模型,为了消除不可消除的个体效应, c_{i} 的表达式为:
c_{it} = \alpha_{0} + \alpha_{1} y_{i0} + \alpha_{2} \overline{x}{i} + \alpha{3} x_{i0} + a_{i} \tag{2}
其中, y_{i0} 、 x_{i0} 是具有动态变化特征变量的初始观测值; \overline{x}_{i} 是个体从时间维度上取均值,即 \overline{x}_{i} = 1/T \sum_{i=0}^{T} x_{it} ; a_{i} 是随机干扰项,服从正态分布。
2.2 模型估计
为便于理解,令 \delta w_{it}^{*} = c_{i} + \beta y_{it-1} + \rho x_{it} + \gamma z_{it} ,则式 (1) 可改写成:
y_{it}^{*} = \delta w_{it}^{*} + \varepsilon_{it} \tag{4}
假设 F \left (\cdot \right) 是 \varepsilon_{it} 的连续单调递增的概率密度分布函数,即 1< F \left (\cdot \right )< 0 ,则有:
\begin{aligned} P\left(y_{i t}=1\right) &=P\left(y_{i t}^{*}>0\right) \\ &=P\left(\varepsilon_{i t}>-\delta w_{i t}^{*}\right) \\ &=1-P\left(\varepsilon_{i t} \leq-\delta w_{i t}^{*}\right) \\ &=1-F\left(-\delta w_{i t}^{*}\right) \end{aligned}
根据逻辑分布的对称性,整理可得: P\left ( y_{it} = 1 \right ) = F\left ( \delta w_{it}^{*} \right) \tag{5}
P\left ( y_{it} = 0 \right ) = 1 - F\left ( \delta w_{it}^{*} \right) \tag{6}
根据 (5) 和 (6),可以将式 (1) 改写成:
y_{it}=E \left ( y_{it} \right ) + \varepsilon_{it} = p_{it} +\varepsilon_{it} = 1 - F\left ( -\delta w_{it}^{*} \right) + \varepsilon_{it} \tag{7}
根据逻辑分布的对称性,式 (7) 可简化成:
y_{it} = F\left ( \delta w_{it}^{*} \right) + \varepsilon_{it} \tag{8}
即 y_{it}关于它的条件均值的一个回归。如果将 F \left (\cdot \right ) 设定为标准正态分布函数 \Phi \left (\cdot \right ) ,即:
F \left (z \right )=\Phi \left (z \right ) = \int_{ - \infty }^{ z } {\frac{1}{\sqrt{2\pi }} e^{-\frac{t^{2}}{2}}} dt \tag{9}
其中, \phi \left( z \right) = {\frac{1}{\sqrt{2\pi }} e^{-\frac{t^{2}}{2}}} 为标准正态分布函数 \Phi \left (\cdot \right ) 的概率密度函数。由此,式 (5) 可以写成 :
P\left ( y_{it} = 1 \right )=F\left ( \delta w_{it}^{*} \right)= \Phi \left (\delta w_{it}^{*} \right ) \tag{10}
非线性模型的估计方法是极大似然法。那么,假设我们有一组随机样本,为了得到以解释变量为条件的极大似然估计量,可将动态面板 Probit 模型改写成:
P\left ( y_{it} \right )=\left [ F\left ( \delta w_{it}^{*} \right) \right ]^{y_{it}} \left [ 1- F\left ( \delta w_{it}^{*} \right) \right ]^{1-y_{it}} ,y=0,1 \tag{11}
其中, i=1,2....N,t=1, 2....T 。显然,当 y_{it}=1 时, P\left ( y_{it} = 1 \right )=F\left (\delta w_{it}^{*} \right) ;当 y_{it}=0 时, P\left ( y_{it} = 0 \right )= 1- F\left ( \delta w_{it}^{*} \right) 。因此,根据式 (11) 可获得似然函数:
L=\prod_{i=1}^{N}\prod_{t=1}^{T}\left [F\left (\delta w_{it}^{*} \right) \right ]^{y_{it}} \left [ 1- F\left (\delta w_{it}^{*} \right) \right ]^{1-y_{it}} \tag{12}
对数似然函数为:
\ln L=\sum_{i=1}^{N} \sum_{t=1}^{T}\left\{y_{i t} \cdot \ln \left[F\left(\delta w_{i t}^{*}\right)\right]+\left(1-y_{i t}\right) \cdot \ln \left[1-F\left(\delta w_{i t}^{*}\right)\right]\right\}\tag{13}
最大化 $lnL$ 的一阶条件为 {\partial lnL}/{\partial \delta}=0 ,即: \frac{\partial lnL}{\partial \delta}=\sum_{i=1}^{N} \sum_{t=1}^{T}\left [ \delta w_{it}^{*} \cdot f\left (\delta w_{it}^{*} \right ) \cdot \frac{y_{it}-F\left ( \delta w_{it}^{*} \right )}{F\left (1- w_{it}^{*} \right )\cdot F\left (\delta w_{it}^{*} \right )}\right ]=0 \tag{14}
其中, F^{'}\left (\delta w_{it}^{*} \right )=f\left (\delta w_{it}^{*} \right ) 。由于式 (14) 式是非线性模型,因此需要用迭代法进行求解,这里不再详细展开。
连享会 最新专题 直播
3. Stata应用
Stata 官方并未提供直接估计动态 Probit 模型的命令。下面,我们先用手动计算的方法估计该模型,进而使用外部命令 xtpdyn 进行估计。前者便于理解模型背后的原理;后者语法简洁,推荐使用。
3.1 数据简介
下文将使用 Grotti and Cutuli (2018) 文中的数据,变量定义如下:
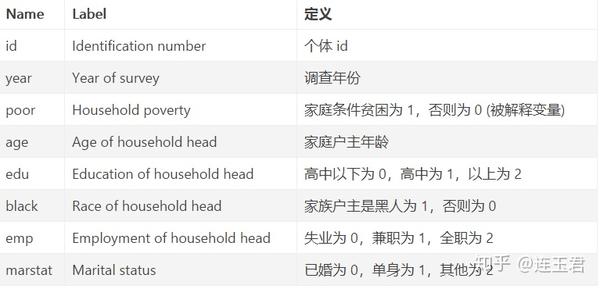

3.2 旧方法 (手动处理)
旧方法的基本步骤如下:
- Step1:预先手动计算具有动态变化特征变量的初始值 \color{red}{y_{i0}}、 \color{red}{x_{i0}} 以及个体均值 \color{red}{\overline{x}_{i}} ,去除不可观测的个体效应;
- Step2:使用 xtprobit}、meprobit 命令对动态数据模型进行估计;
- 以 Grotti and Cutuli (2018,[PDF]) 的例子,命令如下:
*******************************************
* 手动估计动态面板Probit模型
* By-hand replication of model estimation
*******************************************
*-Step1:手动计算相关初始值、个体均值
*-数据概况
use poverty.dta,clear
xtset id year
xtdes
*-去掉缺失值
gen sample = !mi(id, year, poor, black, age, edu, emp, marstat)
*-计算具有动态变化特征变量的初始值
local i "poor age emp marstat"
foreach var of varlist `i' {
bys sample id (year): gen `var'__0 = `var'[1] ///
if sample & sample[1]==1
}
*-计算具有动态变化特征变量的个体均值
bys sample id : egen m__age = mean(age)
bys sample id : egen m1__emp = mean(emp==1)
bys sample id : egen m2__emp = mean(emp==2)
bys sample id : egen m1__marstat = mean(marstat==1)
bys sample id : egen m2__marstat = mean(marstat==2)
*-Step2:估计模型 -xtprobit- -meprobit-
*-用 xtprobit 估计动态数据模型
xtset id year
xtprobit poor iL.poor black c.age i.edu i.emp i.marstat ///
i.poor__0 age__0 i.emp__0 i.marstat__0 ///
m__age m1__emp m2__emp m1__marstat m2__marstat
est store xtp
*-用 meprobit 估计动态数据模型
meprobit poor iL.poor black c.age i.edu i.emp i.marstat ///
i.poor__0 age__0 i.emp__0 i.marstat__0 ///
m__age m1__emp m2__emp m1__marstat m2__marstat || ///
id : , intpoints(12)
est store mep3.3 新方法:外部命令 xtpdyn
Grotti and Cutuli (2018, Stata Journal,[PDF]) 详细介绍了 xtpdyn 命令的原理及用法。
3.3.1 下载安装
在 Stata 命令窗口输入如下命令,即可自动安装 xtpdyn 命令:
ssc install xtpdyn, replace3.3.2 基本语法
xtpdyn 可以用简单的命令生成变量的初始值及个体均值,语法如下:
xtpdyn depvar indepvars [if] [in] [weight], uh(varlist) [re(re_options)]depaver是被解释变量,即模型 (1) 中的 $y_{it}^{*}$;indepvars是解释变量,即模型 (1) 中的 $x_{it} 和 z_{it}$;uh()中放入具有动态变化特征的解释变量,即模型 (1) 中的 $x_{it}$;re()是指随机效应,如果考虑异方差,可写成re(vce(robust))
一个例子 :下面的例子中,xtpdyn 列示了解释变量,以及 poor__0、age__0 等变量初始值,m1__emp、m2__emp 等个体均值的回归结果。net get xtpdyn.pkg // 下载数据
use "poverty.dta", clear
xtset id year
xtpdyn poor black c.age i.edu i.emp i.marstat, ///
uh(i.emp i.marstat age) re(vce(robust))
Iteration 0: log pseudolikelihood = -2101.8697 (not concave)
…… (output omitted) ……
Iteration 7: log pseudolikelihood = -1963.425
Mixed-effects probit regression Number of obs = 6,173
Group variable: id Number of groups = 1,112
Obs per group:
min = 3
avg = 5.6
max = 9
Integration method: mvaghermite Integration pts. = 12
Wald chi2(20) = 1154.68
Log pseudolikelihood = -1963.425 Prob > chi2 = 0.0000
(Std. Err. adjusted for 1,112 clusters in id)
--------------------------------------------------------------------------------
| Robust
poor | Coef. Std. Err. z P>|z| [95% Conf. Interval]
---------------+----------------------------------------------------------------
|
L.poor |
Poor | .5744007 .0813891 7.06 0.000 .414881 .7339205
|
black | .5225842 .0688626 7.59 0.000 .3876159 .6575525
age | -.0649581 .0129398 -5.02 0.000 -.0903197 -.0395966
|
edu |
High School | -.2264437 .0768907 -2.95 0.003 -.3771466 -.0757407
More than HS | -.5724683 .0960026 -5.96 0.000 -.7606299 -.3843067
|
emp |
Part-time | -.4357227 .1355535 -3.21 0.001 -.7014027 -.1700426
Full-time | -1.23497 .1408088 -8.77 0.000 -1.51095 -.9589893
|
marstat |
Single | -.6937395 .2385683 -2.91 0.004 -1.161325 -.2261542
Div/sep/wid | -.5112024 .1342855 -3.81 0.000 -.7743972 -.2480076
|
1.poor__0 | .923642 .095303 9.69 0.000 .7368516 1.110432
|
emp__0 |
1 | -.148413 .1406438 -1.06 0.291 -.4240698 .1272438
2 | -.1200204 .1545567 -0.78 0.437 -.4229458 .1829051
|
marstat__0 |
1 | -.3251233 .1983599 -1.64 0.101 -.7139016 .063655
2 | -.2616084 .1915875 -1.37 0.172 -.637113 .1138962
|
age__0 | -.0311116 .0313137 -0.99 0.320 -.0924852 .0302621
m1__emp | .2515403 .2492729 1.01 0.313 -.2370256 .7401062
m2__emp | -.1801458 .261989 -0.69 0.492 -.6936349 .3333432
m1__marstat | 1.0849 .3453074 3.14 0.002 .4081096 1.76169
m2__marstat | 1.051389 .2589864 4.06 0.000 .5437854 1.558993
m__age | .081758 .0334461 2.44 0.015 .0162049 .147311
_cons | -.1005763 .244535 -0.41 0.681 -.5798561 .3787036
---------------+----------------------------------------------------------------
id |
var(_cons)| .3355826 .0634519 .2316618 .486121
--------------------------------------------------------------------------------3.2.3 辅助语法
第一, xtpdyn 可一键删除或保留新增的变量
xtpdyn [, keep|drop]其中, - keep 保留变量初始值、个体均值等新增的变量;
- drop 删除已保留的变量初始值、个体均值等新增的变量;
第二,probat 命令可用于显示动态面板 Probit 模型估计后的事件发生概率 (Transition Probabilities) 及其他统计信息。
probat, {stats[(atspec)]|prdistr}
[margins(margins_options) nq(#)
showfreq plot keep]stats()选项
①记录进入概率 Pr(1|0) 、退出概率 Pr(0|1) 、持续概率 Pr(1|1) 、稳态概率 \left [ Pr\left ( 1|0 \right )/ Pr\left ( 1|0 \right ) +Pr\left ( 0|1 \right )\right ] 、稳态持久度 [1/Pr(0|1)] 等统计信息;
②输入命令 probat, stats 将提供整个数据的统计结果;
③输入命令 probat, stats\left (varname1= n \right ) 将提供变量 varname1 的统计信息;
④不能与 prdistr 一起使用;
prdistr选项
①计算不同水平 c_{i} 的预期概率 Pr(1|0)、Pr(1|1) 等。 c_{i} 产生差异的原因在于,具有个体间的 y_{i0}、\overline{x}{i} 和 x_{i0} 数值不同;
②通过两个维度区分 c_{i} 的不同水平:第一个维度是被解释变量的初始观测值 y_{i0} ;第二个维度是根据 \overline{x}_{i} 和 x_{i0} 的样本分布 (分位数概念)
magins选项: 计算模型的边际效应nq()选项: 设置计算预期概率时的分位数水平,仅允许 2、3、4、5 和 10 分位数。系统默认为 5 分位数。showfreq选项:显示不同水平 c_{i} 的样本频数plot选项:图示不同水平 c_{i} 的预期概率结果
Stata 范例 1:
- 命令含义是在 3 分位数水平上列示样本分布及
prdistr的统计结果; - 第一张表列示样本分布;
- 第二张表列示统计结果,以第一行为例:在滞后一期的家庭条件为非贫穷 \left ( L.poor=0 \right ) ,家庭条件最初为非贫穷 \left ( poor_0 = 0 \right ) ,年龄、雇佣方式等联合均值在第一分位数上 \left ( poor_0 = 0 \right ) 的情况下,家庭条件由贫穷变为非贫穷的概率是 5.26%。
probat, prdistr nq(3) showfreq
-> poor__0 = 0
--------------------------------------------------------------------------
| 3 quantiles of uhi and Household poverty
poor at | -------- 1 ------- -------- 2 ------- -------- 3 -------
time t-1 | Not poor Poor Not poor Poor Not poor Poor
----------+---------------------------------------------------------------
0 | 1,595 104 1,077 95 1,131 94
1 | 97 55 81 89 73 87
--------------------------------------------------------------------------
-> poor__0 = 1
--------------------------------------------------------------------------
| 3 quantiles of uhi and Household poverty
poor at | -------- 1 ------- -------- 2 ------- -------- 3 -------
time t-1 | Not poor Poor Not poor Poor Not poor Poor
----------+---------------------------------------------------------------
0 | 71 21 152 61 115 57
1 | 53 74 142 351 132 366
--------------------------------------------------------------------------
--------------------------------------------------------------------------------
L.poor#poor__0#uh_q | Prob. Std. Err. P>|z| Lower CI Upper CI
--------------------+-----------------------------------------------------------
0 0 1 | 0.0526 0.005130 0.000 0.0425 0.0626
0 0 2 | 0.0815 0.006289 0.000 0.0692 0.0939
0 0 3 | 0.0972 0.008282 0.000 0.0809 0.1134
0 1 1 | 0.2935 0.027079 0.000 0.2404 0.3466
0 1 2 | 0.4713 0.025980 0.000 0.4203 0.5222
0 1 3 | 0.5119 0.028153 0.000 0.4568 0.5671
1 0 1 | 0.1221 0.017207 0.000 0.0884 0.1559
1 0 2 | 0.1707 0.019060 0.000 0.1334 0.2081
1 0 3 | 0.1950 0.021376 0.000 0.1531 0.2369
1 1 1 | 0.4743 0.028741 0.000 0.4180 0.5307
1 1 2 | 0.6440 0.018173 0.000 0.6083 0.6796
1 1 3 | 0.6843 0.018109 0.000 0.6488 0.7198
--------------------------------------------------------------------------------Stata 范例 2:
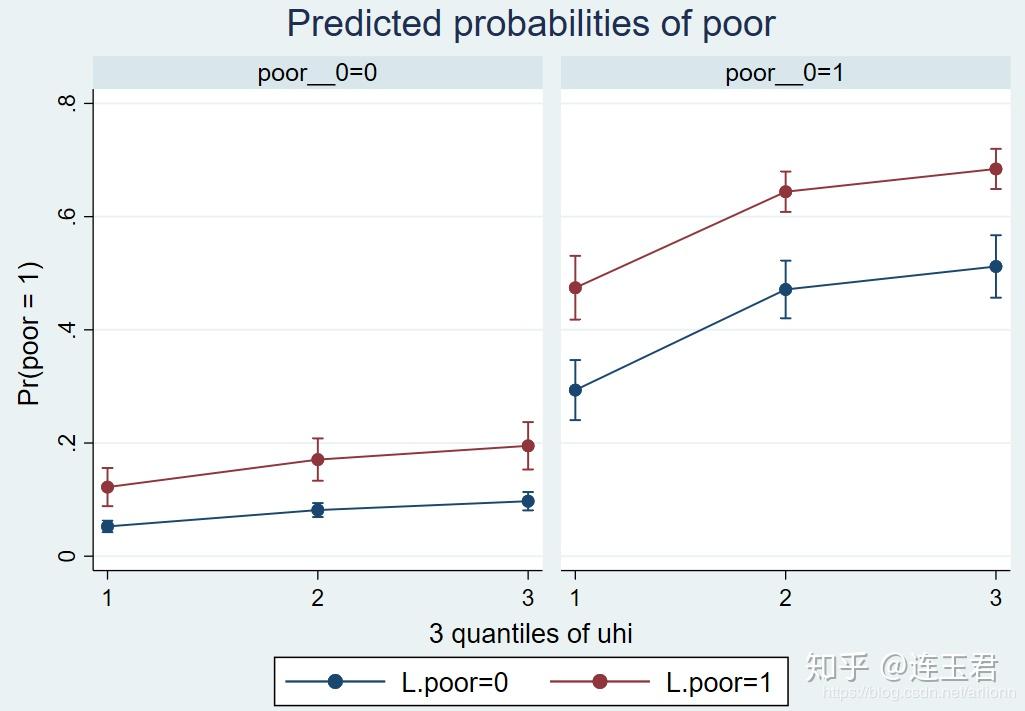
- 图为例子一命令中增加
plot后的结果; - 可读信息一:在控制不可观测的个体效应的基础上,家庭条件初始贫穷时,本期继续贫穷的概率更大;
- 可读信息二:在控制不可观测的个体效应的基础上,上一期家庭条件贫穷时,本期继续贫穷的概率更大;

4. 参考文献
- Grotti, R. and Cutuli, G. Xtpdyn: A community-contributed command for fitting dynamic random-effects probit models with unobserved heterogeneity. The Stata Journal, 2018, 18(4): 844-862. [PDF]
- Rabe-Hesketh, S. and Skrondal, A. Avoiding biased versions of Wooldridge's simple solution to the initial conditions problem. Economics Letters, 2013, 120: 346-349. [PDF]
- Skrondal, A. and S. Rabe-Hesketh, S. Handling initial conditions and endogenous covariates in dynamic/transition models for binary data with unobserved heterogeneity. Journal of the Royal Statistical Society, 2014, 63(C): 211–237. [PDF]
- Wooldridge, J. M. Simple solutions to the initial conditions problem in dynamic, nonlinear panel data models with unobserved heterogeneity. Journal of Applied Econometrics, 2005, 20: 39-54. [PDF]
相关课程
连享会-直播课 上线了!
http://lianxh.duanshu.com
免费公开课:
- 直击面板数据模型 - 连玉君,时长:1 小时 40 分钟
- Stata 33 讲 - 连玉君, 每讲 15 分钟.
- 部分直播课 课程资料下载 (PPT,dofiles 等)

Note: 助教招聘信息请进入「课程主页」查看。
因果推断-内生性 专题 ⌚ 2020.11.12-15
主讲:王存同 (中央财经大学);司继春(上海对外经贸大学)
课程主页:https://gitee.com/arlionn/YG | 微信版
http://qr32.cn/BlTL43 (二维码自动识别)
空间计量 专题 ⌚ 2020.12.10-13
主讲:杨海生 (中山大学);范巧 (兰州大学)
课程主页:https://gitee.com/arlionn/SP | 微信版
https://gitee.com/arlionn/DSGE (二维码自动识别)

关于我们
- Stata 连享会 由中山大学连玉君老师团队创办,定期分享实证分析经验。直播间 有很多视频课程,可以随时观看。
- 连享会-主页 和 知乎专栏,300+ 推文,实证分析不再抓狂。
- 公众号推文分类:计量专题 | 分类推文 | 资源工具。推文分成 内生性 | 空间计量 | 时序面板 | 结果输出 | 交乘调节 五类,主流方法介绍一目了然:DID, RDD, IV, GMM, FE, Probit 等。

连享会小程序:扫一扫,看推文,看视频……

扫码加入连享会微信群,提问交流更方便

