一文读懂Transformer和Attention

本文来自外网的一篇英文文章,对transformer和attention的讲解非常细致清晰,有兴趣的可以读原文《The Illustrated Transformer》。
这篇文章,我们将会深入transformer-一个采用attention加速训练的模型。transformer在一些特定任务上超过了Google Neural Machine Translation模型。transformer最大的优势是并行化,谷歌甚至将transformer作为他们cloud tpu推广的示例模型。因此,我们拆解模型的细节然后看下它到底是如何工作的。
-------------------------------------------------------------------------------------------
一文读懂系列文章:
图神经网络GNN相关系列文章:
《什么是Weisfeiler-Lehman(WL)算法和WL Test?》
《图神经网络库PyTorch geometric(PYG)零基础上手教程》
-------------------------------------------------------------------------------------------
抽象思想
我们首先将transformer模型看作一个简单的黑盒。在机器翻译应用里面,模型将一种语言的句子作为输入,然后输出另一种语言的表示。


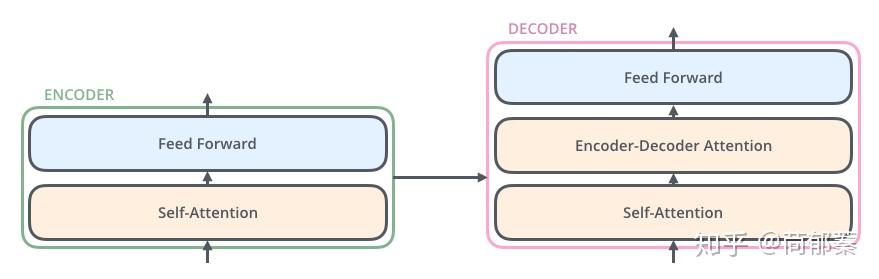
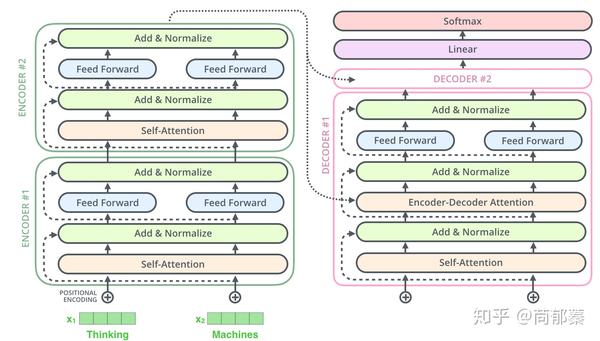
深入到组件内部,由编码组件、解码组件和它们之间的连接层组成。
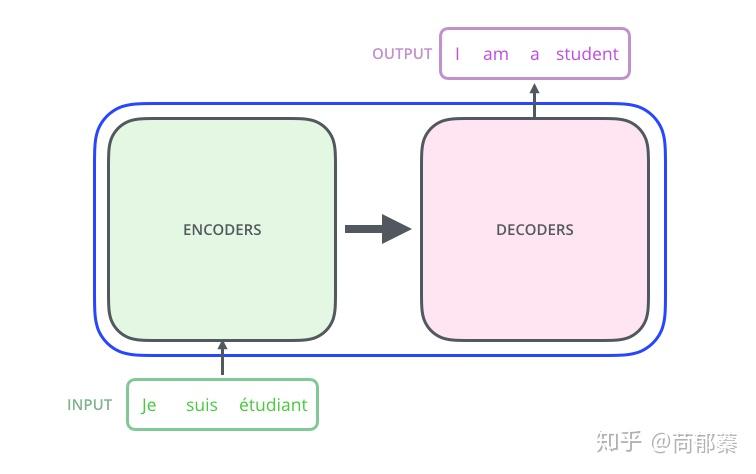

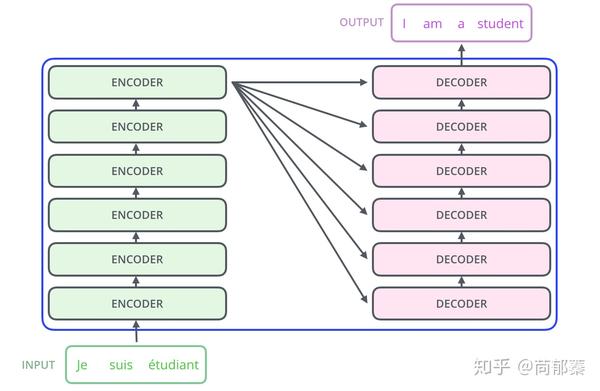
编码组件是六层编码器首位相连堆砌而成,解码组件也是六层解码器堆成的。

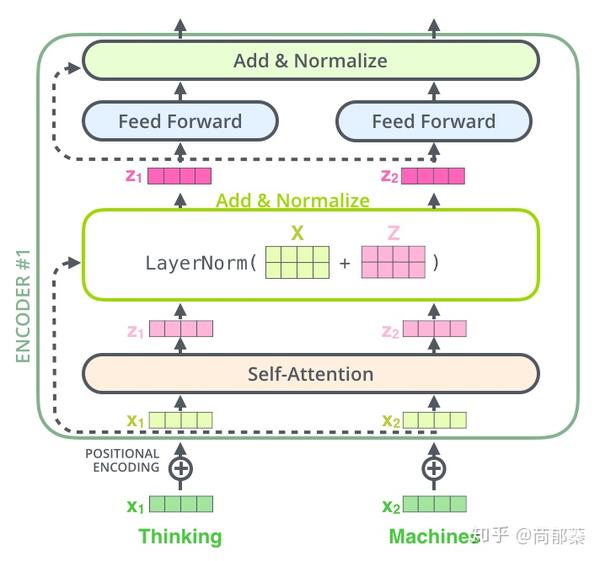
每一层的编码器结构完全相同(但不共享参数),每一个编码器都可以拆解成以下两个部分。
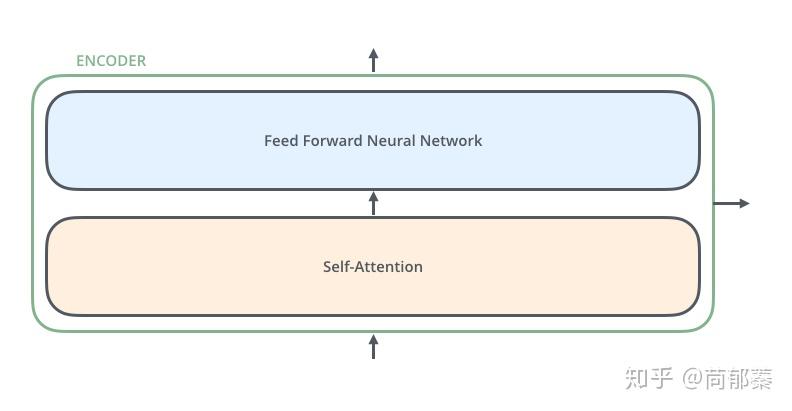

编码器的输入首先通过self-attention层,该层作用是在编码具体一个单词时考虑输入序列中的其他单词的影响。self-attention的内部结构会在后面的部分详细介绍。
self-attention的输出流向一个前向网络,每个输入位置对应的feed-forward网络是独立互不干扰的。
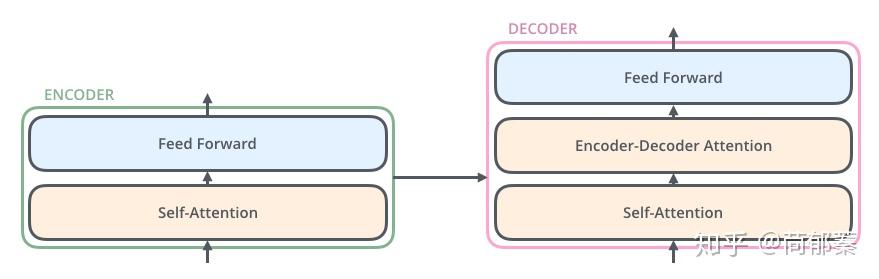
解码器同样也有这些子层,但是在两个子层间增加了attention层,该层有助于解码器能够关注到输入句子的相关部分,与 seq2seq model的Attention作用相似。
tensor
现在,我们解析下模型最主要的组件,各种各样的vector/tensor开始,然后是它们如何流经各个组件们并输出的。
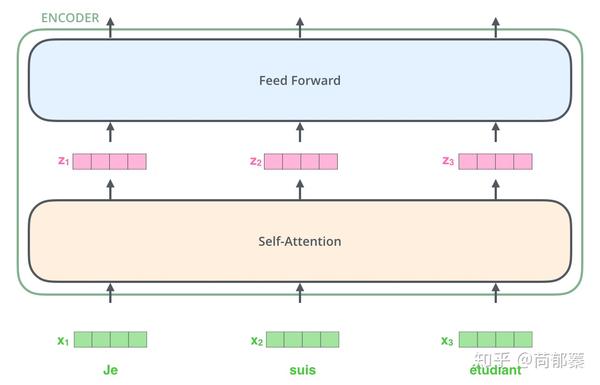
正如NLP应用的常见例子,先将输入单词使用embedding algorithm转成向量。


此处用这些小方格表示词向量,假设词向量维度为512
最底层的编码器的输入为词向量,其他编码器的输入是前个编码器的输出。这样每个编码器的都会接收到一个list(list的每个元素都是512维的词向量)。list的尺寸是可以设置的超参,通常是训练集的最长句子的长度。
在对输入序列向量化之后,它们流经编码器的如下两个子层。
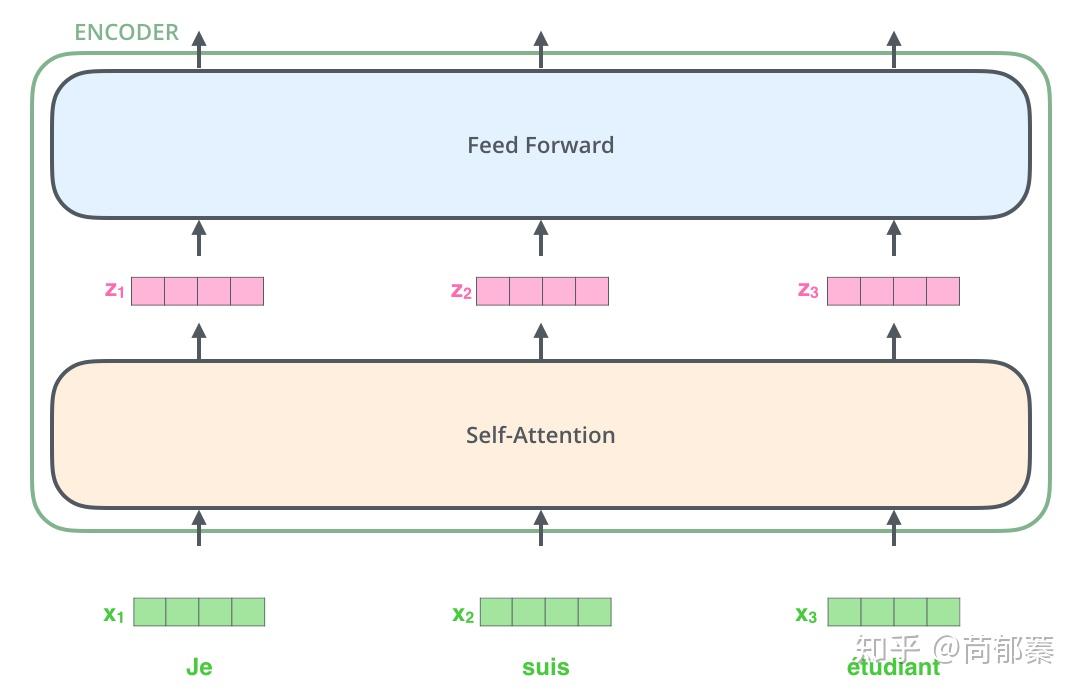
这里能看到Transformer的一个关键特性,每个位置的词仅仅流过它自己的编码器路径。在self-attention层中,这些路径之间是相互依赖的。而feed-forward层则没有这些依赖性,这些路径在流经feed-forward层时可以并行执行。
编码器部分
正如之前所提,编码器接收向量的list作输入。然后将其送入self-attention处理,再之后送入前向网络,最后将输入传入下一个编码器。
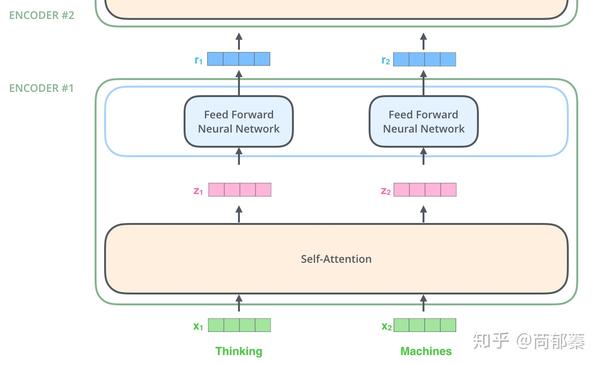
每个位置的词向量被送入self-attention模块,然后是feed-forward层(对每个向量都是完全相同的网络结构)
Self-Attention的含义
不要被self-attention这个词迷惑了,看起来好像每个人对它都很熟悉,但是在我读到Attention is All You Need这篇文章之前,我个人都没弄懂这个概念。下面我们逐步分解下它是如何工作的。
以下面这句话为例,作为我们想要翻译的输入语句“The animal didn’t cross the street because it was too tired”。句子中"it"指的是什么呢?“it"指的是"street” 还是“animal”?对人来说很简单的问题,但是对算法而言并不简单。
当模型处理单词“it”时,self-attention允许将“it”和“animal”联系起来。当模型处理每个位置的词时,self-attention允许模型看到句子的其他位置信息作辅助线索来更好地编码当前词。如果你对RNN熟悉,就能想到RNN的隐状态是如何允许之前的词向量来解释合成当前词的解释向量。Transformer使用self-attention来将相关词的理解编码到当前词中。


当编码"it"时(也就是编码器的最后层it部分的输出),部分attention集中于"the animal",并将其表示合并进入到“it”的编码中
上图是Tensor2Tensor notebook的可视化例子
Self-Attention细节
我们先看下如何计算self-attention的向量,再看下如何以矩阵方式计算。
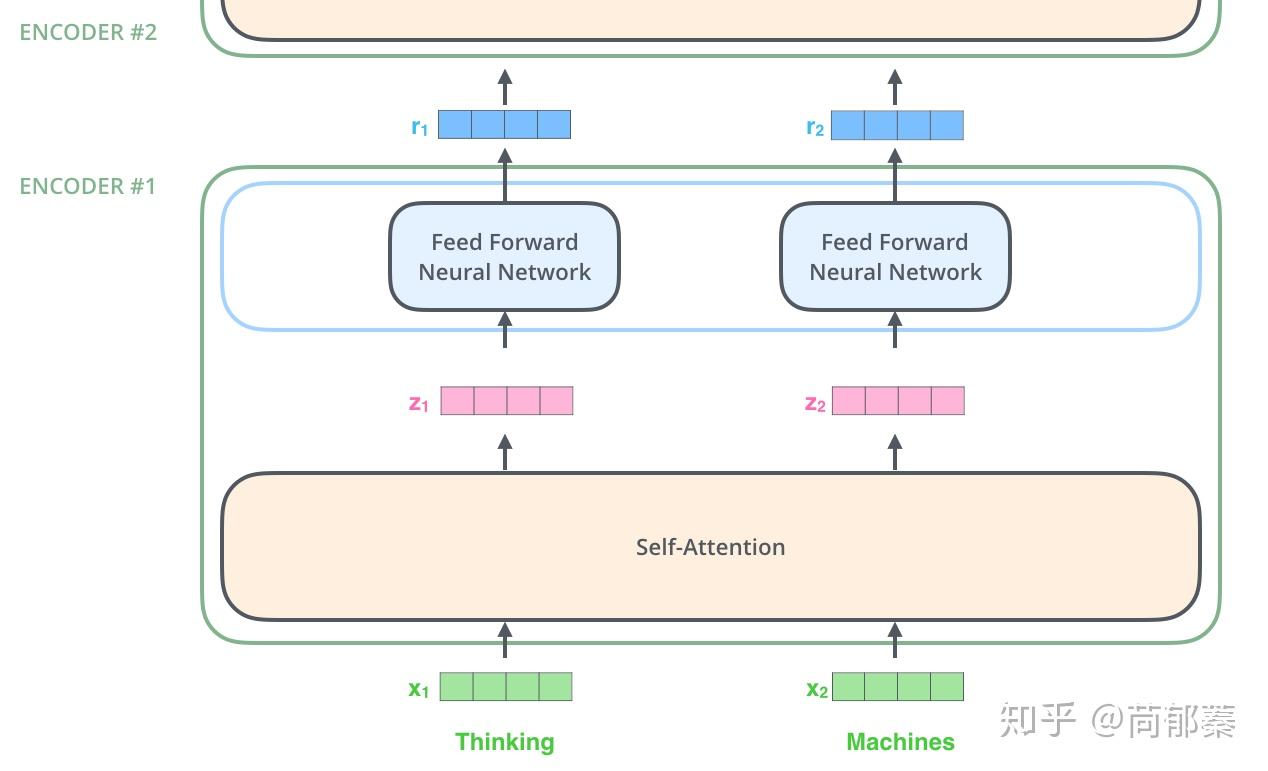
第一步,根据编码器的输入向量,生成三个向量,比如,对每个词向量,生成Query vector, Key vector, Value vector,生成方法为分别乘以三个矩阵,这些矩阵是训练过程中需要学习的参数。
【注意:不是每个词向量独享3个matrix,而是所有输入共享3个转换矩阵;权重矩阵是基于输入位置的转换矩阵】
注意到这些新向量的维度比输入词向量的维度要小(512–>64),这是出于网络结构上的考虑,是为了让多头attention的计算更稳定。
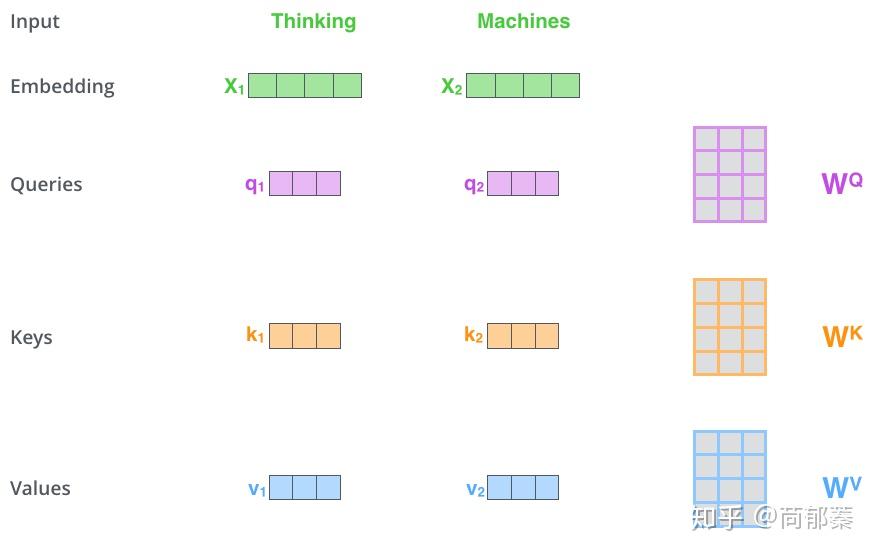

所谓的Query vector, Key vector, Value vector是什么?
这种提取对计算和思考attention是有益的,当读完下面attention是如何计算的之后,你将对这些向量的角色有更清晰的了解。
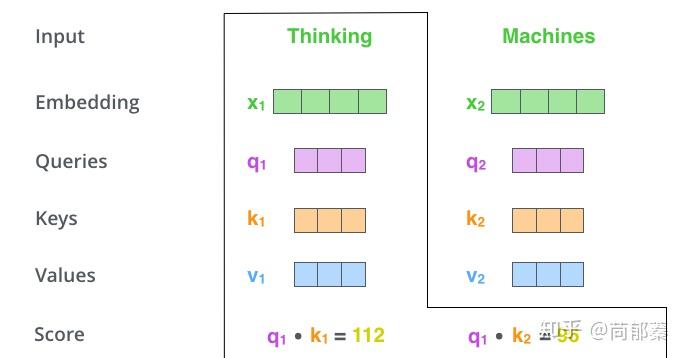
第二步,计算attention就是计算一个分值。举个例子,对“Thinking Machines”这句话,对“Thinking”计算attention 分值。我们需要计算其他每个词与“Thinking”的相关分,这个分决定着编码“Thinking”时,其他每个输入词需要集中多少关注度。
这个分,通过“Think”对应Query vector与所有词的Key vector依次做点积得到。所以当我们处理位置“Think”时,第一个分值是q1和k1的点积,第二个分值是q1和k2的点积。

第三步和第四步,除以8(paper中采用维度64的平方根,这样梯度会更稳定,可以为其他的值)。然后加上softmax操作,归一化分值使得全为正数且加和为1。
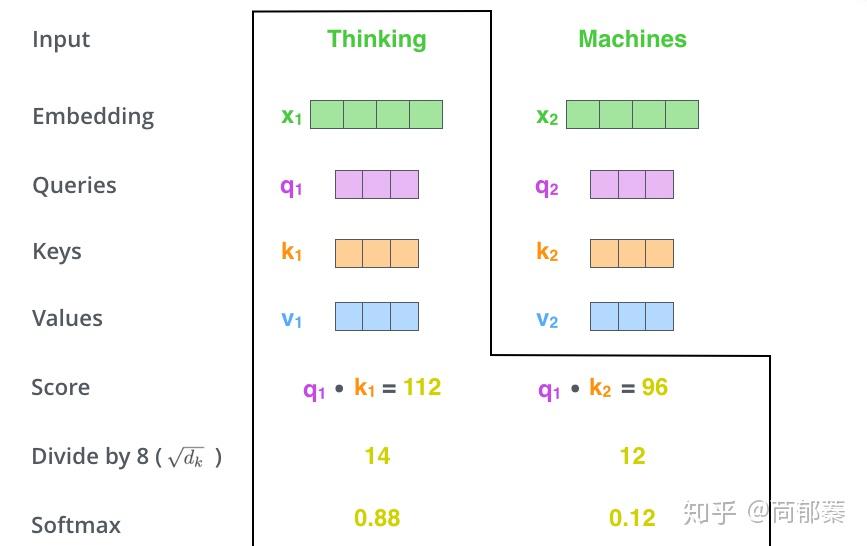

softmax分值决定着在这个位置,每个词的表达程度(关注度)。很明显,这个位置的词应该有最高的归一化分数,但大部分时候总是有助于关注该词的相关的词。
第五步,将softmax分值与Value vector按位相乘。保留关注词的value值,削弱非相关词的value值。
第六步,将所有加权向量加和,产生该位置的self-attention的输出结果。


上述就是self-attention的计算过程,生成的向量流入前向网络。在实际应用中,上述计算是以速度更快的矩阵形式进行的。下面我们看下在单词级别的矩阵计算。
Self-Attention的矩阵计算形式
第一步,计算query/key/value matrix,将所有输入词向量合并成输入矩阵X,并且将其分别乘以权重矩阵Wq,Wk,Wv。
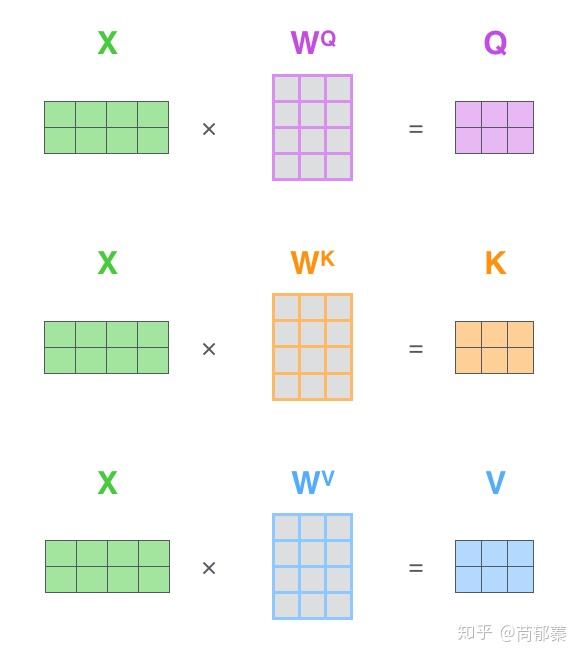

输入矩阵X的每一行表示输入句子的一个词向量
最后,鉴于我们使用矩阵处理,将步骤2~6合并成一个计算self-attention层输出的公式。
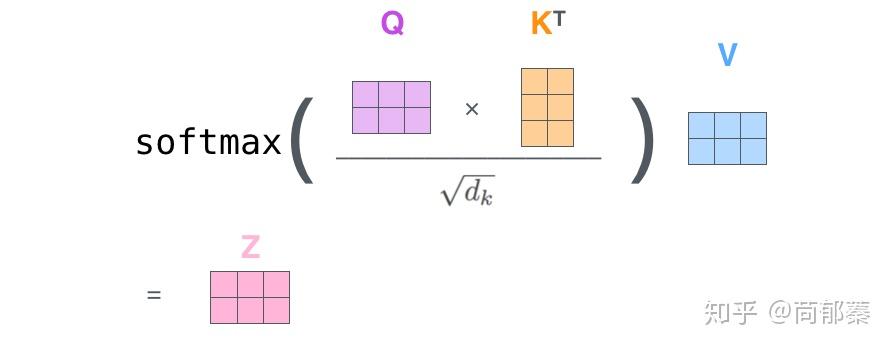

Multi-Headed Attention
论文进一步增加了multi-headed的机制到self-attention上,在如下两个方面提高了attention层的效果:
- 多头机制扩展了模型集中于不同位置的能力。在上面的例子中,z1只包含了其他词的很少信息,仅由实际自己词决定。在其他情况下,比如翻译 “The animal didn’t cross the street because it was too tired”时,我们想知道单词"it"指的是什么。
- 多头机制赋予attention多种子表达方式。像下面的例子所示,在多头下有多组query/key/value-matrix,而非仅仅一组(论文中使用8-heads)。每一组都是随机初始化,经过训练之后,输入向量可以被映射到不同的子表达空间中。
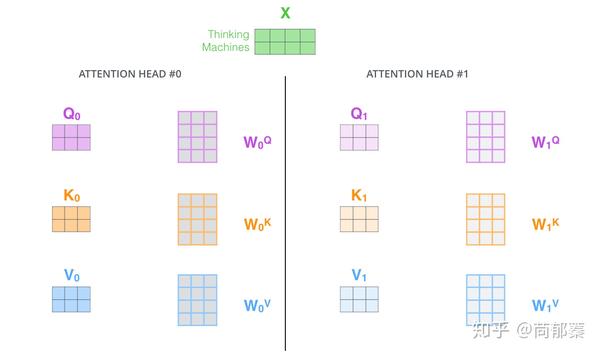

如果我们计算multi-headed self-attention的,分别有八组不同的Q/K/V matrix,我们得到八个不同的矩阵。
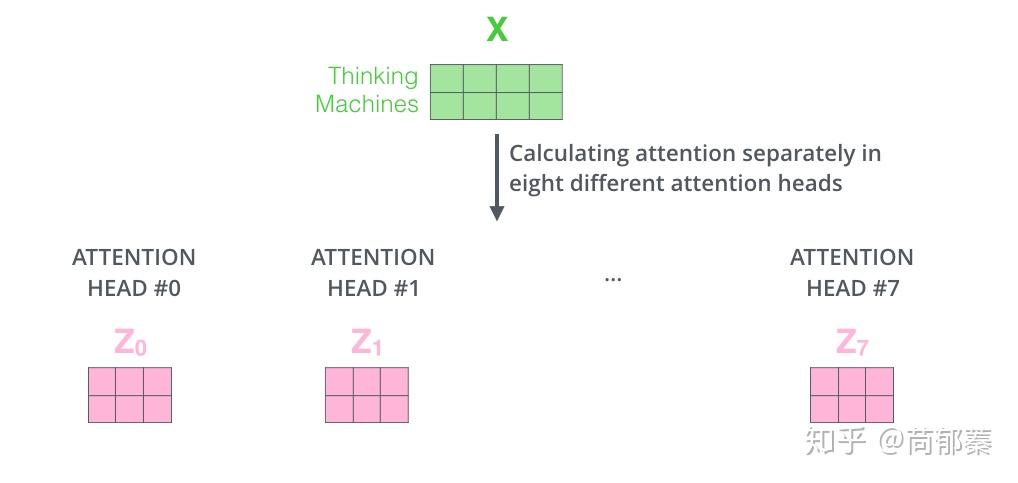
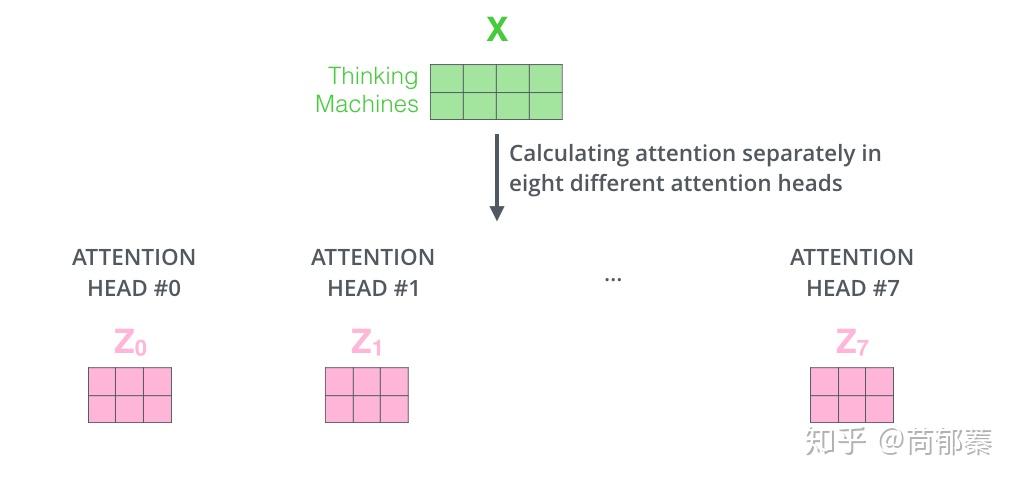
这会带来点麻烦,前向网络并不能接收八个矩阵,而是希望输入是一个矩阵,所以要有种方式处理下八个矩阵合并成一个矩阵。那么怎么办?做过网络经验比较多的就能想到,再用一个可训练的权重矩阵W^O去乘以八个矩阵连接起来的矩阵,通过设计权重矩阵W^O的维度使得最终的Z矩阵维度为我们想要的样子。
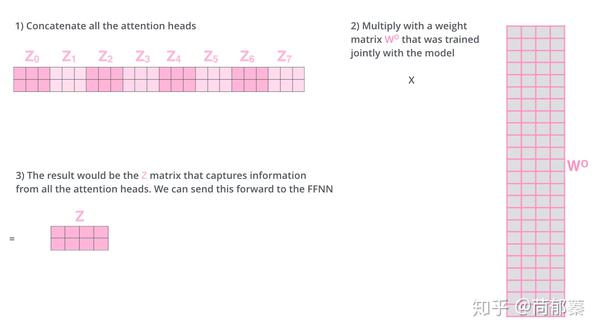

上述就是多头自注意机制的内容,我认为还仅是一部分矩阵,下面尝试着将它们放到一个图上可视化如下。
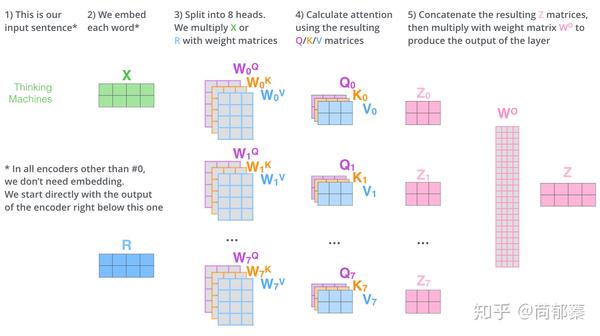

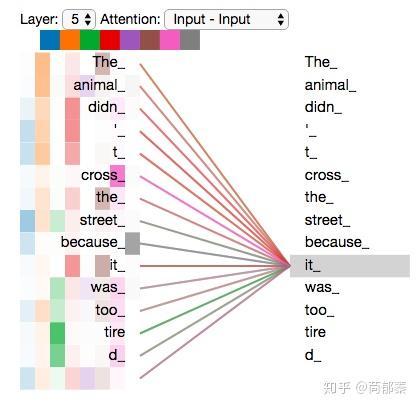
现在加入attention heads之后,重新看下当编码“it”时,哪些attention head会被集中。


如图为两个head可视化的结果,编码"it"时,一个attention head(橙色)集中于"the animal",另一个head(绿色)集中于“tired”,某种意义上讲,模型对“it”的表达合成了的“animal”和“tired”两者
如果我们将所有的attention heads都放入到图中,就很难直观地解释了,但可以从更多的方面获取其他位置的信息。
位置编码
截止到目前为止,我们还没有讨论如何理解输入语句中词的顺序。
为解决词序的利用问题,Transformer新增了一个向量对每个词,这些向量遵循模型学习的指定模式,来决定词的位置,或者序列中不同词的举例。对其理解,增加这些值来提供词向量间的距离,当其映射到Q/K/V向量以及点乘的attention时。
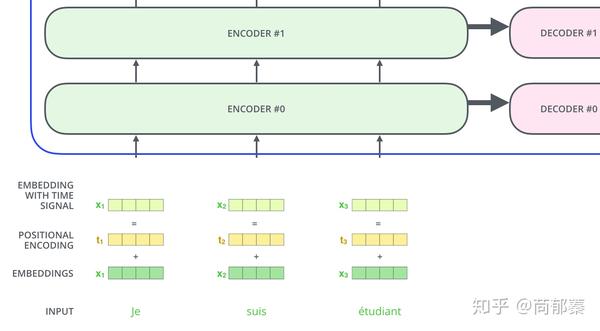

为了能够给模型提供词序的信息,新增位置embedding,每个embedding值都遵循指定模式
如果假设位置向量有4维,实际的位置向量将如下所示:
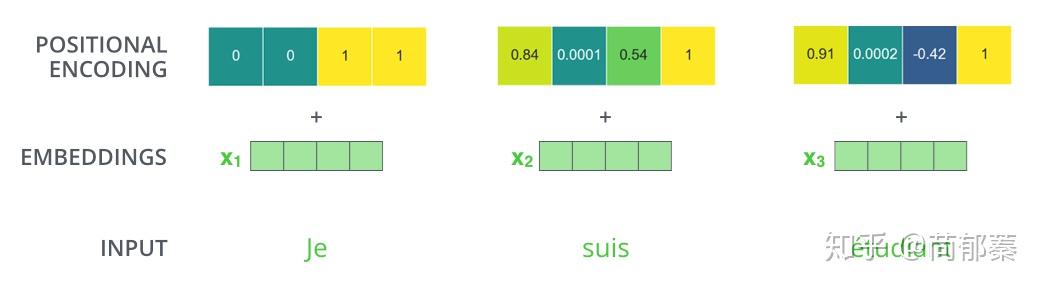

一个只有4维的位置向量表示例子
所谓的指定模式是什么样的呢?
在下图中,每一行表示一个位置的pos-embedding,所以第一行是我们将要加到句子第一个词向量上的vector。每个行有512值,每个值范围在[-1,1],我们将要涂色以便于能够将模式可视化。
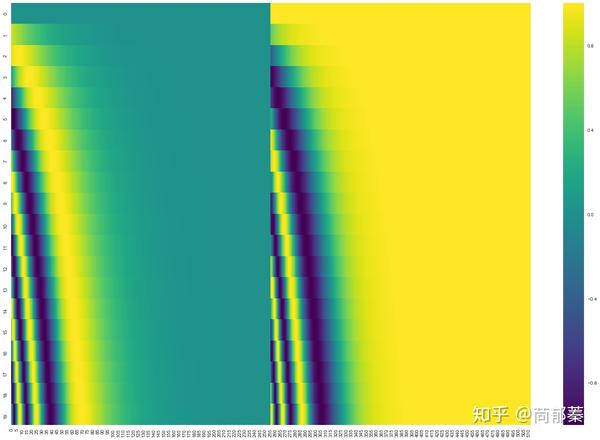

一个真实的例子有20个词,每个词512维。可以观察中间显著的分隔,那是因为左侧是用sine函数生成,右侧是用cosine生成。
位置向量编码方法在论文的3.5节有提到,也可以看代码get_timing_signal_ld(),对位置编码而言并不只有一种方法。需要注意的是,编码方法必须能够处理未知长度的序列。
The Residuals
编码器结构中值得提出注意的一个细节是,在每个子层中(slef-attention, ffnn),都有残差连接,并且紧跟着layer-normalization。
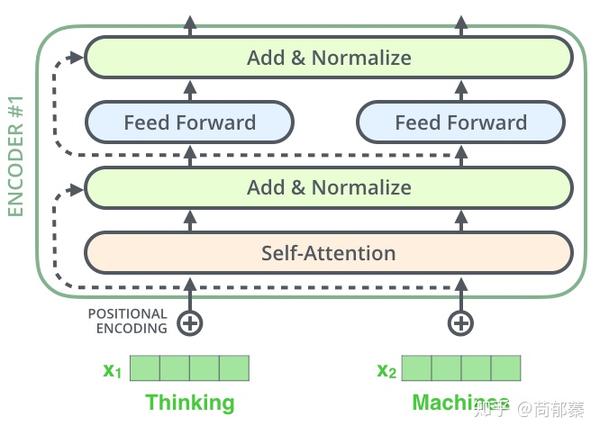

如果我们可视化向量和layer-norm操作,将如下所示:
在解码器中也是如此,假设两层编码器+两层解码器组成Transformer,其结构如下:


解码器部分
现在我们已经了解了编码器侧的大部分概念,也基本了解了解码器的工作方式,下面看下他们是如何共同工作的。
编码器从输入序列的处理开始,最后的编码器的输出被转换为K和V,它俩被每个解码器的"encoder-decoder atttention"层来使用,帮助解码器集中于输入序列的合适位置。
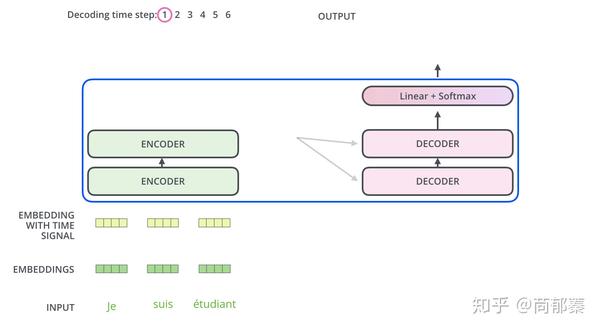

在编码之后,是解码过程;解码的每一步输出一个元素作输出序列
下面的步骤一直重复直到一个特殊符号出现表示解码器完成了翻译输出。每一步的输出被喂到下一个解码器中。正如编码器的输入所做的处理,对解码器的输入增加位置向量。
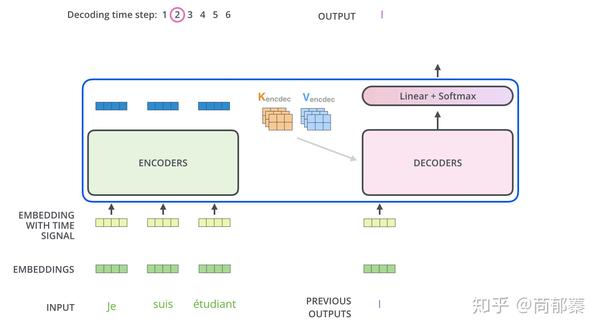

在解码器中的self attention 层与编码器中的稍有不同,在解码器中,self-attention 层仅仅允许关注早于当前输出的位置。在softmax之前,通过遮挡未来位置(将它们设置为-inf)来实现。
"Encoder-Decoder Attention "层工作方式跟multi-headed self-attention是一样的,除了一点,它从前层获取输出转成query矩阵,接收最后层编码器的key和value矩阵做key和value矩阵。
Linear and Softmax Layer
解码器最后输出浮点向量,如何将它转成词?这是最后的线性层和softmax层的主要工作。
线性层是个简单的全连接层,将解码器的最后输出映射到一个非常大的logits向量上。假设模型已知有1万个单词(输出的词表)从训练集中学习得到。那么,logits向量就有1万维,每个值表示是某个词的可能倾向值。
softmax层将这些分数转换成概率值(都是正值,且加和为1),最高值对应的维上的词就是这一步的输出单词。
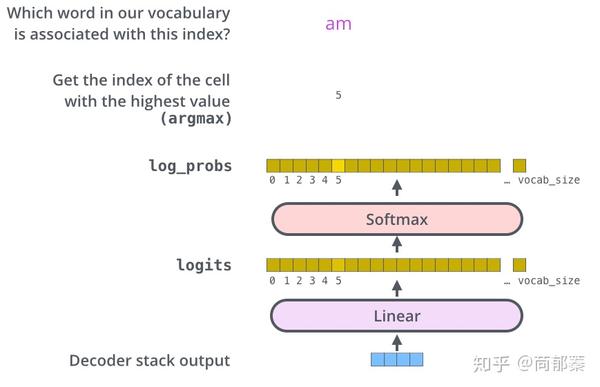

训练过程
现在我们已经了解了一个训练完毕的Transformer的前向过程,顺道看下训练的概念也是非常有用的。
在训练时,模型将经历上述的前向过程,当我们在标记好了的训练集上训练时,可以对比预测输出与实际输出。
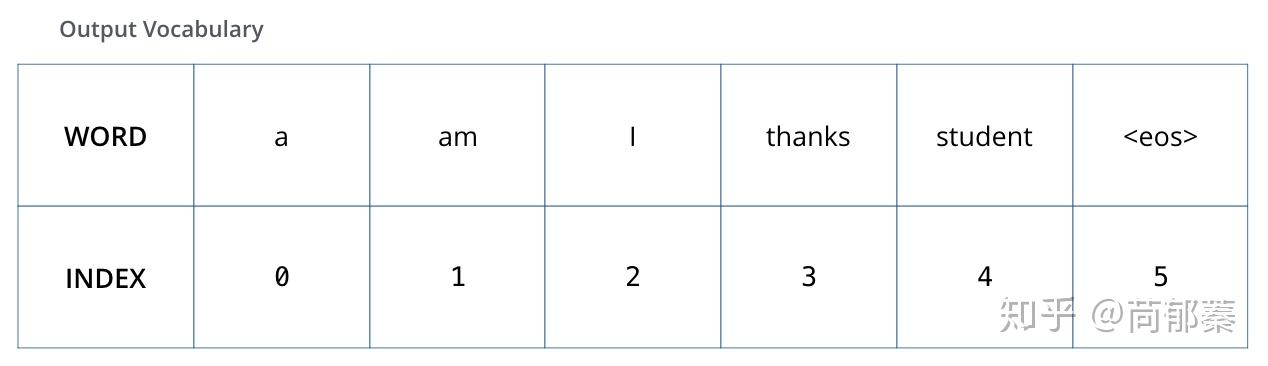
为了可视化,假设输出词表一共只有6个单词(“a”, “am”, “i”, “thanks”, “student”, “”),模型的词表是在训练之前的预处理中生成的。

一旦定义了词表,我们就能够构造一个同维度的向量来表示每个单词,比如one-hot编码,下面举例编码“am”。
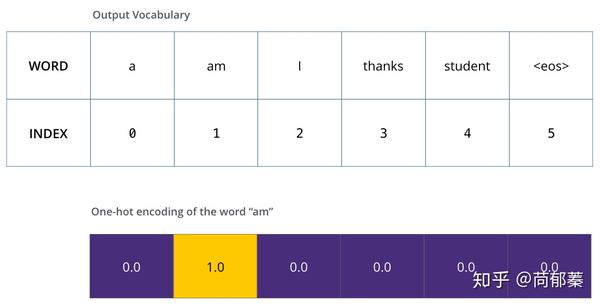

举例采用one-hot编码输出词表
下面让我们讨论下模型的loss损失,也就是在训练过程中用来优化的指标,通过减少这个指标来指导模型学习。
损失函数
我们用一个简单的例子来示范训练,比如翻译“merci”为“thanks”。那意味着输出的概率分布指向单词“thanks”,但是由于模型未训练是随机初始化的,不太可能就是期望的输出。
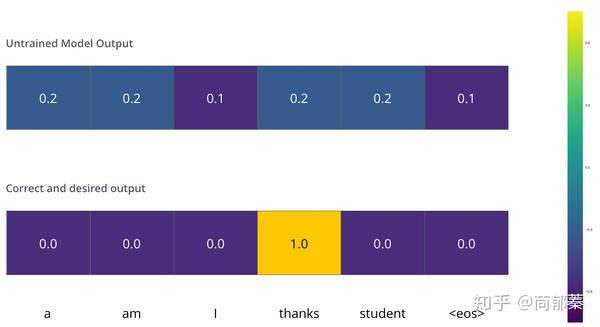

由于模型参数是随机初始化的,未训练的模型输出随机值。我们可以对比真实输出,然后利用误差后传调整模型权重,使得输出更接近与真实输出
如何对比两个概率分布呢?简单采用 cross-entropy或者Kullback-Leibler divergence中的一种。
鉴于这是个极其简单的例子,更真实的情况是,使用一个句子作为输入。比如,输入是“je suis étudiant”,期望输出是“i am a student”。在这个例子下,我们期望模型输出连续的概率分布满足如下条件:
1 每个概率分布都与词表同维度。
2 第一个概率分布对“i”具有最高的预测概率值。
3 第二个概率分布对“am”具有最高的预测概率值。
4 一直到第五个输出指向""标记。
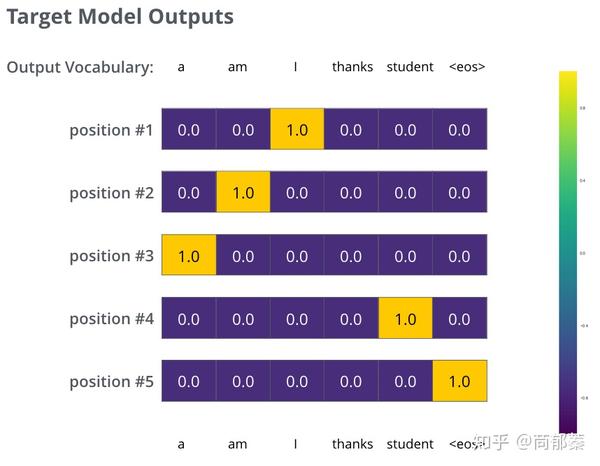

对一个句子而言,训练模型的目标概率分布
在足够大的训练集上训练足够时间之后,我们期望产生的概率分布如下所示:
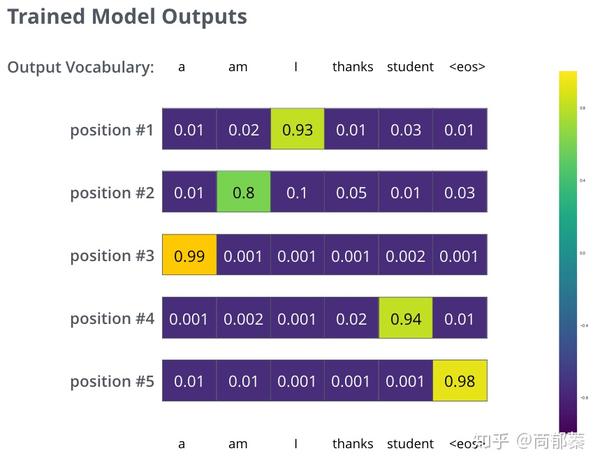
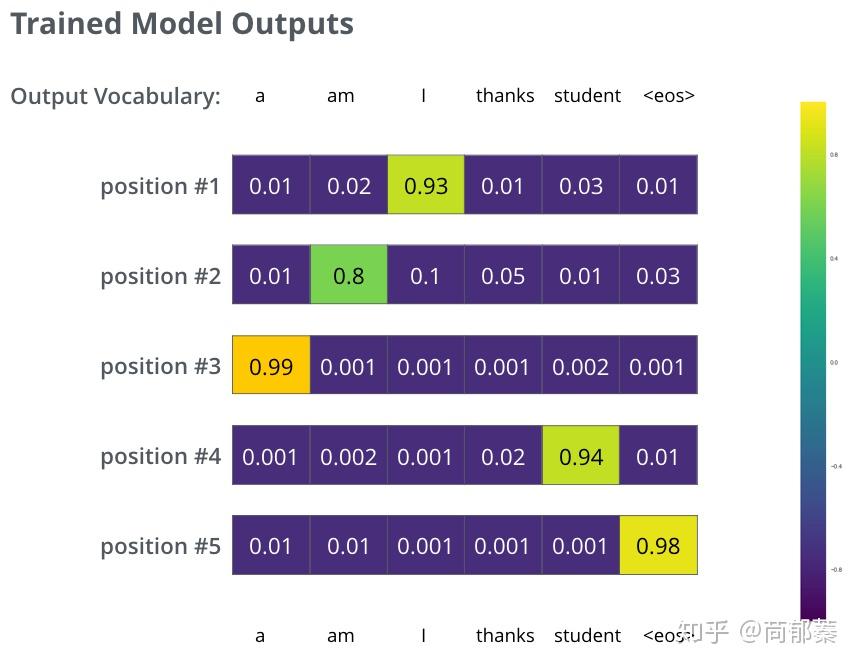
训练好之后,模型的输出是我们期望的翻译。当然,这并不意味着这一过程是来自训练集。注意,每个位置都能有值,即便与输出近乎无关,这也是softmax对训练有帮助的地方。
现在,因为模型每步只产生一个输出单词,最简单的思路是模型选择最高概率的单词,扔掉其他的部分,这是一种产生预测结果的方法,叫做greedy 解码。另外一种方法是beam search,比如说每一步仅保留最头部高概率的两个输出(例如I和am),下一步则根据根据这两种输出分别运行模型,一次假设上一次的输出为I,一次假设上一次的输出为am,再保留头部高概率的两个输出,重复直到序列预测结束。其中,beam_size为2,因为一次计算两个单词,top_beams也为2,因为每次保留,两个都是超参可试验调整。
