详解web缓存

一、啥是缓存
1. 缓存
在解释web缓存前,为方便理解,我们先来聊一聊缓存(cache),这个词来源于计算机硬件,由于CPU运算速度极快,而内存和硬盘的读写速度相对来说又特别慢,所以CPU每次有数据存取需要的时候,就要等待磁盘的缓慢操作,这对于CPU的性能是极大的浪费,所以为了快速响应CPU需求,需要有一个快速的存储设备来临时存放数据,这便是缓存。解释得不够专业,以下是一段截自百度百科(缓存)的解释:
定义:原始意义是指访问速度比一般随机存取存储器(RAM)快的一种高速存储器,通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术。缓存的设置是所有现代计算机系统发挥高性能的重要因素之一。
原理:缓存的工作原理是当CPU要读取一个数据时,首先从CPU缓存中查找,找到就立即读取并送给CPU处理;没有找到,就从速率相对较慢的内存中读取并送给CPU处理,同时把这个数据所在的数据块调入缓存中,可以使得以后对整块数据的读取都从缓存中进行,不必再调用内存。正是这样的读取机制使CPU读取缓存的命中率非常高(大多数CPU可达90%左右),也就是说CPU下一次要读取的数据90%都在CPU缓存中,只有大约10%需要从内存读取。这大大节省了CPU直接读取内存的时间,也使CPU读取数据时基本无需等待。总的来说,CPU读取数据的顺序是先缓存后内存。
2. web缓存
扯了这么多,其实web缓存的产生和原理跟上面一样一样的:客户端浏览器在显示一个完整网页前,需要去服务器获取一些必要的数据(js,css,image等),因为浏览器的数据处理和渲染速度很快,而通过网络传输的方式去服务器取数据的过程却很慢(虽然现在网速还算比较快,下载1M的文件都用不了1s,但相较于处理器,这就非常慢了),所以页面显示出来前都有一段时间的白屏,如果每次打开相同的页面,获取相同的资源都要等待一段时间的白屏,作为用户,岂能忍。如果把已经获取过的资源存在本地,下次用的时候就不用从服务器去取了,这样速度就要快很多了。这种机制便是web缓存。
其实web缓存的优点还有很多: - 减轻服务器压力 - 减少数据传输,节省网络带宽和流量 - 缩短页面加载时间,提升用户体验
二、web缓存分类
了解了缓存的由来和原理,下面针对web缓存(以下统一简称缓存)具体介绍一下。缓存是一个抽象的代名词,用以提高访问效率而临时存储副本的机制都可以称之为缓存。我们常说的缓存,根据资源存放位置、具体用途和运行机制不同,一般可以分为:
- 数据库缓存
- 服务器缓存
- 客户端缓存
下面有一张图能解释一番:
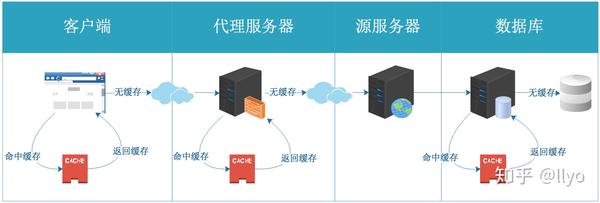

1. 数据库缓存
一般常见的web应用,特别是复杂的大型应用,数据库的数据表众多,数据量大,在做数据查询时需要花费一定的时间和大量的性能,所以为了避免频繁的数据查询,数据库服务器会将查询到的数据暂存在内存中,下次有相同数据查询时可以直接从内存中返回,极大的提高了性能和效率。常见的数据库缓存技术有memcache和redis。
2. 服务器缓存
又称为缓存代理服务器或者代理缓存,是存在于客户端和源服务器之间的一种中间服务器,这种代理服务器接收多个客户端的数据请求,属于公有缓存,这种缓存能大量减少多个客户端相同的资源请求,有效降低源服务器的负载压力。
3. 客户端缓存
这里的客户端缓存一般指的是浏览器缓存,即浏览器端将符合规范条件的资源存储在客户端本地的一种存储机制,下面是截自百度百科(浏览器缓存)的一段解释:
浏览器缓存(Browser Caching)是为了节约网络的资源加速浏览,浏览器在用户磁盘上对最近请求过的文档进行存储,当访问者再次请求这个页面时,浏览器就可以从本地磁盘显示文档,这样就可以加速页面的阅览。
三、浏览器缓存
浏览器经过过年的发展,产生过很多存储机制,有些已经淘汰(如早期IE的userData),有些正在逐步淘汰(如Web SQL DataBase),有些新的也在产生(如H5新提出的File System Api),总结下来,当前比较流行、被广泛使用的浏览器缓存大概分以下几种:
- HTTP缓存
- Web Storage
- App Cache
- IndexedDB
- File System Api
1. HTTP缓存
即http协议缓存,浏览器根据http协议头部的特殊控制字段来控制资源缓存的机制。根据http协议版本的不同,用于控制缓存的头部字段主要分为下面两类
http1.0
http1.1
1.1 http1.0
Pragma: 是否使用缓存。可选值为no-cache,告诉浏览器在使用缓存前要发请求到服务器进行验证,不可直接使用缓存Expires: 缓存的过期日期,单位为秒。值为一个具体的日期,例如Tue, 27 Oct 2020 05:56:47 GMT,告诉浏览器在这个过期日期之前都可以直接使用缓存
Pragma为http1.0的产物,已逐步被http1.1的cache-control:no-cache替代,功能一致。http1.1响应首部中出现的Pragma:no-cache只是为了兼容http1.0,实际Cache-Control的优先级更高。
Pragma和Expires同时存在时,Expires不会生效,即Pragma的优先级要高于Expires
Expires的值是一个具体的时间点,这个时间点是相对于服务器的时间,如果客户端的时间和服务器时间不一致,比如手动修改客户机系统时间,那么这个“过期时间”的作用可能会出现偏差,或者说失效
1.2 http1.1
Cache-Control: 更细粒度的控制是否可以缓存,可选值如下
no-store: 强制禁止所有缓存,禁止保存资源副本,所有资源的请求必需和首次请求一样,从服务器获取资源。no-cache: 无论缓存是否过期,都禁止直接使用缓存(即客户端可以保存资源副本),每次请求资源时,需要向源服务器发送验证请求,服务器接收到请求,然后判断资源是否变更,是则返回200和新内容,否则返回304使用缓存副本。max-age=n: 表示缓存可用的有效时长,值为一个数字,单位为秒,例如max-age=31536000,表示自请求时间开始,1年内有效s-maxage=n: 作用同max-age一样,只是针对的是代理服务器public: 表示代理服务器和客户端都可以缓存资源private: 表示资源是私有的,只针对单个用户、实体或者窗口进行缓存,不可公用must-revalidate: 缓存过期前,可以直接使用缓存副本,但是缓存一旦过期,就必须向源服务器发送验证请求max-stale=n: 用法类似max-age,但只在请求头部有效,表示客户端愿意接收一个过期的版本,该资源的过期时间不能超过给定的时间n。
Cache-Control可以设置多个值,以,分隔,例如Cache-Control: no-cache,max-age=3600
关于Cache-Control,应该分为请求设置和响应设置,这里也只是列举了一些常用的值,更多内容和细节可以查看这里
2. Last-Modified/If-Modified-Since: 资源过期后,用于与服务器验证资源时使用,值为资源的最后修改时间
Last-Modified: 响应头部中的标识,值为一个具体的GMT(格林威治)时间,表示的是资源最后的修改时间,由服务器返回给客户端,供资源过期时,客户端向服务器发送验证请求时使用If-Modified-Since: 请求头部中的标识,当资源过期后,需要向服务器发送验证请求,如果过期的缓存副本中包含了Last-Modified,那验证请求的头部会带上If-Modified-Since标识,值为缓存副本中Last-Modified的值,服务器获取该值后与资源当前最后修改时间做比较,如果最后修改时间小于或等于请求值,则返回304并更新相关缓存值,如果最后修改时间较新,说明资源被修改过,则返回200和新资源,对应更新缓存
3. Etag/If-None-Match: 资源过期后,用于与服务器验证资源时使用,值是资源的唯一标识(hash值),作用与Last-Modified/If-Modified-Since一致,但是比后者的验证更有效
Etag: 响应头部中的标识,用于表示资源内容唯一性的标识,该值由服务器生成,生成规则由服务器自行决定,一般是文件大小(size)、修改时间(time)、索引(index)等数据Hash后生成。服务器在响应客户请求时可以带上Etag值,供资源过期时,客户端向服务器发送验证请求时使用。If-None-Match: 请求头部中的标识,当资源过期后,需要向服务器发送验证请求,如果过期的缓存副本中包含了Etag,那验证请求的头部会带上`If-None-Match标识,值为缓存副本中Etag的值,服务器获取该值后与资源当前hash值做比较,如果相同,则返回304并更新相关缓存值,如果不相同,说明资源被修改过,则返回200和新资源,对应更新缓存。
1.3 Last-Modified和Etag
从上面的解释可以看出,Cache-Control用于控制缓存和缓存时间,Last-Modified和Etag用于缓存过期时,与服务器做验证时使用,那么问题来了
- 有了
Last-Modified为什么还需要Etag?
Last-Modified的值单位为秒。如果服务资源在1秒内发生多次变更,那服务器通过秒级对比就没办法发现文件是否已经变更。- 一些特殊场景下,有些资源会被定时更新或者修改,但是其内容并未发生改变,而最后修改时间却在变化,导致客户端缓存定期失效,没有达到使用缓存的目的。
- 服务器可能因为一些其他原因,其时间没有与代理服务器或客户端时间保持一致,因时间偏差,从而导致缓存失效。
2. 有了Etag为什么还需要Last-Modified?
Etag的值是服务器计算出的一串hash值,如果计算过程较复杂,比较消耗性能,那使用Last-Modified会比较合适- 如果获取某些文件的最后修改时间比较容易,而文件的变更频率也不高,那无疑使用
Last-Modified更合适
ETag比较的是响应内容的特征值,而Last-Modified 比较的是响应内容的修改时间。这两个是相辅相成的。服务器可以根据自己缓存机制的需要,选择ETag或者是Last-Modified来做缓存判断的依据,甚至可以两个同时参考。
Etag和Last-Modified同时存在时,服务器会优先判断Etag,如果Etag的值相同会继续判断Last-Modified,最后才决定是返回200还是304状态
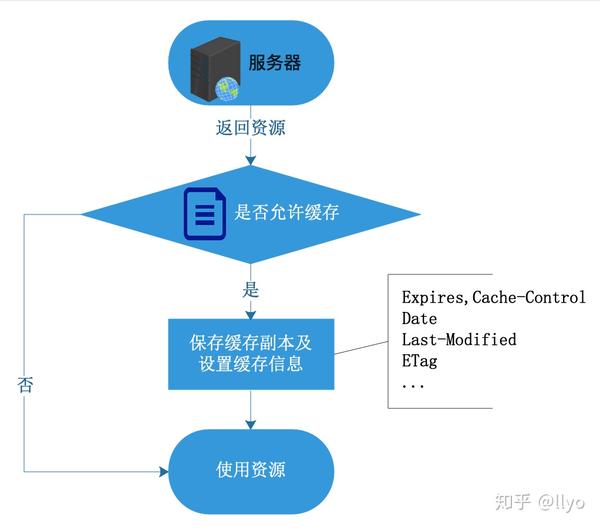
1.4 缓存处理流程
- 资源响应阶段 即无缓存或首次请求,服务器返回资源后

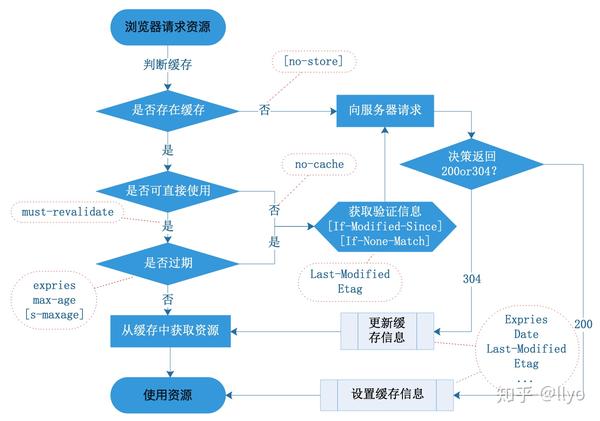
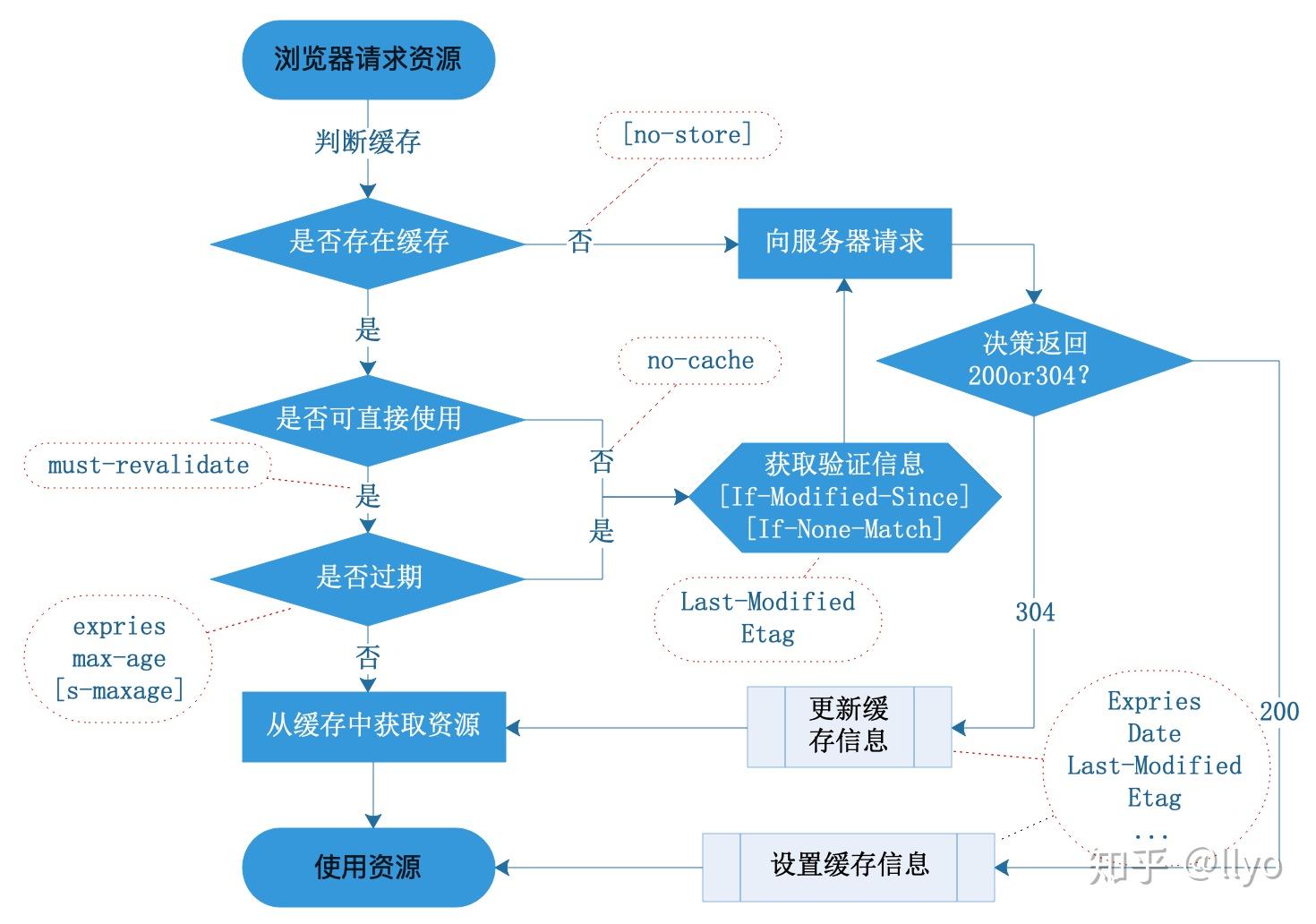
2. 资源二次请求阶段 即需要使用资源时,判断如何使用缓存阶段
2. Web Storage
在介绍Web Storage之前,有必要先讲一下cookie。在没有Web Storage之前,客户端浏览器存储数据都是通过cookie来实现的。cookie因其自身的特性,在一些方面有其独有的优势,比如可配置过期时间、可跨域共享(具有相同祖先域名时)、与服务器数据交互等,但在做数据存储方面,其缺点显而易见:
- 客户端发送请求时,cookie会作为头部将无用数据一起发送给服务器
- 请求被拦截后,cookie数据有泄漏和被篡改的安全风险
- cookie存储数据的大小被限制在4K。IE8、Firefox、opera每个域对cookie的数量也有限制,上限是50,Safari/WebKit没有限制。
以下是获取和设置cookie的方法
// 根据name获取cookie
function getCookie(name) {
if (document.cookie.length > 0) {
let c_start = document.cookie.indexOf(name + "=");
if (c_start != -1) {
c_start = c_start + name.length + 1;
let c_end = document.cookie.indexOf(";", c_start);
if (c_end == -1) c_end = document.cookie.length;
return unescape(document.cookie.substring(c_start, c_end));
}
}
return ""
}
// 设置cookie,name/value为名和值,params为参数
function setCookie(name, value, params = {}) {
let { expires, ...args } = params;
if (expires) {
const date = new Date();
expires = new Date(date.setDate(date.getDate() + expires)).toGMTString();
}
let cookie = `${name}=${escape(value)};expires=${expires}`;
Object.keys(args).forEach(key => {
cookie += `;${key}=${args[key]}`;
});
document.cookie = cookie;
}
因此cookie不适合做大数据量的存储,相比之下,Web Storage更适合存储大量数据:
- 每个域名下可提供5M的存储容量(不同浏览器可能有差异,比如IE是10M)
- 以key/value键值对的方式存储字符串,方便数据存取操作
- 只存储在客户端本地,不会随请求发送给服务端
Web Storage分为两种,即sessionStorage和localStorage,两种对象的使用方法和api基本相同:
const storage = sessionStorage || localStorage;
// 设置xxx的值为'yyy'
storage.setItem('xxx', 'yyy');
// 获取xxx的值
storage.getItem('xxx');
// 删除xxx及其值
storage.removeItem('xxx');
// 获取键值对的数量
storage.length;
// 清空所有值
storage.clear();
以下是sessionStorage和localStorage之间的区别:
- sessionStorage 为每一个给定的源(given origin)维持一个独立的存储区域,该存储区域在页面会话期间可用(即只要浏览器处于打开状态,包括页面重新加载和恢复)。
- localStorage 同样的功能,但是在浏览器关闭,然后重新打开后数据仍然存在。
更多内容可以看这里
3. App Cache
3.1 manifest介绍
即Application Cache,随着移动端H5的流行,HTML5 提供一种 应用程序缓存(Cache Manifest) 机制,使得基于web的应用程序可以离线运行。开发人员需要为浏览器指定需要缓存的文件,在客户端离线的情况下,即使刷新页面,相关资源也可以正常加载和使用。离线缓存具有以下优势:
- 离线浏览: 用户可以在离线状态下浏览网站内容。
- 更快的速度: 因为数据被存储在本地,所以速度会更快。
- 减轻服务器的负载: 浏览器只会下载在服务器上发生改变的资源。
3.2 实现步骤
要实现离线存储,需要几个简单的设置步骤:
- 在服务器上添加manifest文件对应扩展名的
MIME-TYPE支持,让服务器能够识别该manifest文件
manifest文件可以是任意扩展名,但必须以正确的 MIME 类型提供,默认扩展名为.manifest
2. 创建一个后缀名为.manifest 的文件,把需要缓存的文件按格式写在里面,并用注释行标注版本,示例如下:
CACHE MANIFEST
# v1 2019-08-14
# 需要缓存的文件(相对路径)
index.html
cache.html
style.css
image1.png
# NETWORK配置指定的文件,必需始终从服务器获取
NETWORK:
network.html
# FALLBACK配置指定的文件是作为后备使用,例如无法与服务器连接时
FALLBACK:
index.html fallback.htmlCACHE:这是缓存文件中记录所属的默认段落。在 CACHE: 段落标题后(或直接跟在 CACHE MANIFEST行后)列出的文件会在它们第一次下载完毕后缓存起来。
NETWORK: 段落标题下列出的文件是需要与服务器连接的白名单资源。所有类似资源的请求都会绕过缓存,即使用户处于离线状态。可以使用通配符。
FALLBACK: 段指定了一个后备页面,当资源无法访问时,浏览器会使用该页面。该段落的每条记录都列出两个URI—第一个表示资源,第二个表示后备页面。两个 URI 都必须使用相对路径并且与清单文件同源。可以使用通配符。
3. 给 <html> 标签添加 manifest 属性,并引用 manifest 文件
<html manifest="xxx/yyy/appcache.manifest">3.3 应用及更新
- 第一次访问HTML页面(引用了manifest文件)时,发送请求,将获取到的 manifest 文件缓存在本地,并获取文件中需要缓存的资源进行缓存。
- 下次访问时,无论客户端是否离线,都会直接从缓存中获取入口页 HTML 和其他缓存的文件进行展示。与此同时,如果在线,浏览器会异步发送请求到服务器请求manifest文件,并与缓存的manifest副本进行比对,如果发现版本不一致,会陆续发送请求重新拉取入口文件HTML和需要缓存的文件并更新本地缓存副本
3.4 小结
AppCache虽然是HTML5提供的一种新的机制,也流行了一段时间,但是实际应用效果却并不好:
- 更新的资源,需要二次刷新才会被页面采用
- 不支持增量更新,只有manifest发生变化,所有资源全部重新下载一次
- 缺乏足够容错机制,当清单中任意资源文件出现加载异常,都会导致整个manifest策略运行异常
这也导致这种这种机制的没落,该特性已经从 Web 标准中删除,虽然一些浏览器目前仍然支持它,但也许会在未来的某个时间停止支持,所以还是建议尽量不要使用。
4. IndexedDB
4.1 背景
为了实现客户端缓存,虽然已经有很多技术被不断推出和应用,但是随着浏览器功能的不断增强和完善,现有的缓存技术,其局限性也变得越来越明显:
- 容量太小: cookie和Web Storage最多也就支持5M,已经不能满足需求了
- 检索不方便: cookie和Web Storage都是以字符串形式存储数据,复杂对象数据存取前需要做处理,比较麻烦
- 不能提供搜索功能,不能建立自定义的索引
这些就是 IndexedDB(Indexed DataBase)诞生的背景,从字面上可以看出,这就是浏览器提供的本地数据库。IndexedDB可以被网页脚本创建和操作。IndexedDB 允许储存大量数据,提供查找接口,还能建立索引。这些都是 Web Storage 所不具备的。
4.2 特点
IndexedDB 具有以下特点:
- 键值对储存: IndexedDB 内部采用对象仓库(object store)存放数据。所有类型的数据都可以直接存入,包括 JavaScript 对象。对象仓库中,数据以"键值对"的形式保存,每一个数据记录都有对应的主键,主键是独一无二的,不能有重复,否则会抛出一个错误。
- 异步: IndexedDB 操作时不会锁死浏览器,用户依然可以进行其他操作,这与 LocalStorage 形成对比,后者的操作是同步的。异步设计是为了防止大量数据的读写,拖慢网页的表现。
- 支持事务: IndexedDB 支持事务(transaction),这意味着一系列操作步骤之中,只要有一步失败,整个事务就都取消,数据库回滚到事务发生之前的状态,不存在只改写一部分数据的情况。
- 同源限制: IndexedDB 受到同源限制,每一个数据库对应创建它的域名。网页只能访问自身域名下的数据库,而不能访问跨域的数据库。
- 储存空间大: IndexedDB 的储存空间比 LocalStorage 大得多,一般来说不少于 250MB,甚至没有上限。
- 支持二进制储存: IndexedDB 不仅可以储存字符串,还可以储存二进制数据(ArrayBuffer 对象和 Blob 对象)。
以上特点摘自阮老师的文章,具体内容请看这里
4.3 使用
- 创建或打开一个IndexedDB数据库
// 创建或打开数据库
const myDB = window.indexedDB.open('myDB', 1);
// 数据库连接成功
myDB.addEventListener('success', e => {
console.log("数据库连接成功~");
});
// 数据库连接失败
myDB.addEventListener('error', e => {
console.log("数据库连接失败~");
});
使用indexedDB.open()方法创建或者打开一个数据库(新建数据库与打开数据库是同一个操作。如果指定的数据库不存在,就会新建)。该方法接受两个参数,第一个是数据库名称,第二个是对应数据库的版本号,创建后返回一个IDBOpenDBRequest对象,可以通过监听这个对象的success事件和error事件来执行相应的操作。
2. 创建一个对象仓库
对象仓库(Object Store)是 indexedDB 数据库的基础,熟悉数据库的朋友都知道数据库表的含义,这个对象仓库(以下统一简称仓库)其实就类似于数据库中表的概念。
const myDB = indexedDB.open('myDB', 2);
myDB.addEventListener('upgradeneeded', e => {
const dbResult = e.target.result;
// 创建一个"用户信息"仓库 UserInfo
const createdStore = dbResult.createObjectStore(
'UserInfo',
{
keyPath: 'id',
autoIncrement: false
}
);
});
创建仓库必须在upgradeneeded事件回调中进行
如果indexedDB.open()方法指定的版本号,大于数据库的实际版本号,就会发生数据库升级事件upgradeneeded,此时通过事件对象的target.result属性,拿到数据库实例。
使用createObjectStore()方法创建一个仓库,该方法接受两个参数,第一个是仓库名(即数据库概念中的表名),第二个参数可选,keyPath用于指定仓库的主键,如果不配置keyPath,也可以设置autoIncrement:true,指定主键为一个递增的整数。
使用createIndex()方法新建索引,该方法的三个参数分别为索引名称、索引所在的属性、配置对象(说明该属性是否包含重复的值)。
注意,仓库名不可重复,所以最好在创建仓库前通过dbResult.objectStoreNames.contains('testName')判断仓库是否存在3. 创建事务
事务这个关键词不太好理解,简单点说就是在一次数据库操作的过程中,为了保持数据的一致性,要么一次性成功,要么就都失败,不允许出现一些数据操作成功了而另一些操作失败的情况出现,以下是事务的几个特性:
- 原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行
- 一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态的含义是数据库中的数据应满足完整性约束
- 隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行
- 持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中
const myDB = indexedDB.open('myDB', 3);
myDB.addEventListener('success', e => {
const dbResult = e.target.result;
const dbTrans = dbResult.transaction('UserInfo', 'readwrite');
});
使用transaction()方法来创建一个事务。该方法接受两个参数,第一个要操作的仓库名称(可以是仓库名称组成的数组),第二个是创建的事务模式(即操作类型)。readonly表示只能对仓库进行读操作,readwrite表示可进行读写操作。
4. 数据操作
即数据的增、删、查、改操作,数据操作都是以事务的方式进行,在数据操作前首先是获取事务对象,通过事务对象的objectStore()方法获取具体的仓库
// 打开数据库,获取dbResult对象
// ...
// 创建事务
const dbTrans = dbResult.transaction(['UserInfo'], 'readwrite');
// 获取仓库
const dbStore = dbTrans.objectStore('UserInfo');
// 后续其他操作
// ...
注:dbResult.transaction()方法的第二个参数默认值为'readonly',在查询操作时可省略;在增、删、改操作时需要设置为'readwrite'
- 新增数据: 即往仓库中添加一条新数据
// 使用add()方法,参数为一条数据对象
const dbRequest = dbStore.add({
id: 1,
name: '张三',
age: 20,
email: 'zhangsan@example.com'
});
dbRequest.onsuccess = e => {
console.log('数据添加成功~');
};
dbRequest.onerror = e => {
console.log('数据添加失败~');
};
- 查找数据: 即查找数据仓库中某一条数据
// 使用get()方法,参数为主键的值,即示例中id==1的数据
const dbRequest = dbStore.get(1);
dbRequest.onsuccess = e => {
const { result } = dbRequest;
if (result) {
const { name, age, email } = result;
console.log('name:', name);
console.log('age:', age);
console.log('email:', email);
} else {
console.log('未查到对应数据');
}
};
dbRequest.onerror = e => {
console.log('数据查询失败~');
};
- 遍历数据 即遍历数据表格的一批记录,要使用指针(又称游标)对象IDBCursor。
// 使用openCursor()方法
const dbRequest = dbStore.openCursor();
dbRequest.onsuccess = e => {
const dbCursor = e.target.result;
if (dbCursor) {
const { key, value } = dbCursor;
console.log('id:', key);
console.log('name:', value.name);
console.log('age:', value.age);
console.log('email:', value.email);
dbCursor.continue();
} else {
console.log('已遍历完所有数据~');
}
};
dbRequest.onerror = e => {
console.log('数据查询失败~');
};
openCursor(query, direction)方法可以接受两个参数,不传参数时默认选择对应仓库的所有记录
query:要查询的键或者 IDBKeyRange 。如果传一个有效的键,则会默认为只包含此键的范围。如果此参数不传值,则默认为一个选择了该对象存储空间全部记录的键范围
一个 IDBCursorDirection 来告诉游标要移动的方向。可选值有 'next' 、'nextunique' 、'prev' 和 'prevunique'。默认值是 'next'。
这里有个 IDBKeyRange的实验例子,可以试试,方便理解。下面是 IDBKeyRange 相关方法的解释和栗子 ,
// bound()方法表示一个集合 即主键值从m到n(包含m和n)的集合。
// 如果第三个参数为true,则表示不包含最小键值m,如果第四参数为true,则表示不包含最大键值n,默认都为false
const boundRange = IDBKeyRange.bound(m, n, false, false);
// only('x')方法表示返回主键值为'x'的记录。参数为主键值。
const onlyRange = IDBKeyRange.only('x');
// lowerRaneg(m) 表示大于等于m的主键值的集合。
// 第二个参数可选,为true则表示不包含最小主键m,false则包含,默认为false
const lowerRange = IDBKeyRange.lowerBound(m, false);
// upperRange(n) 表示小于等于n的主键值的集合。
// 第二个参数可选,为true则表示不包含最大主键n,false则包含,默认为false
const upperRange = IDBKeyRange.upperBound(n, false);
// includes('x')方法是以上range对象实例的方法,返回一个Boolean值,表示当前集合中是否包含主键值为'x'的记录
// myKeyRange为(boundRange | onlyRange | lowerRange | upperRange)
myKeyRange.includes('x');
下面是 IDBCursorDirection 值的一些栗子
// next : 游标中的数据按主键值升序排列,主键值相等的数据都被读取
const nextDiraction = 'next';
// nextunique : 游标中的数据按主键值升序排列,主键值相等只读取第一条数据
const nextuniqueDiraction = 'nextunique';
// prev : 游标中的数据按主键值降序排列,主键值相等的数据都被读取
const prevDiraction = 'prev';
// prevunique : 游标中的数据按主键值降序排列,主键值相等只读取第一条数据
const prevuniqueDiraction = 'prevunique';
完整的栗子 如下:
const myDB = indexedDB.open('myDB', 4);
myDB.addEventListener('success', e => {
const dbResult = e.target.result;
const dbTrans = dbResult.transaction('UserInfo');
const dbStore = dbTrans.objectStore('UserInfo');
const boundRange = IDBKeyRange.bound(1,5);
const dbRequest = dbStore.openCursor(boundRange, 'next');
dbRequest.onsuccess = e => {
const dbCursor = dbRequest.result || e.target.result;
if (dbCursor){
const { key, value } = dbCursor;
console.log('id:', key);
console.log('name:', value.name);
console.log('age:', value.age);
console.log('email:', value.email);
dbCursor.continue();
} else {
console.log('编辑完毕~');
}
};
});
- 删除数据 即删除仓库中的某一条数据
// 使用delete()方法,参数为主键的值
const dbRequest = dbStore.delete(1);
dbRequest.onsuccess = e => {
console.log('数据删除成功~');
};
dbRequest.onerror = e => {
console.log('数据删除失败~');
};
- 更新数据 即修改仓库中的某一条数据
// 使用put()方法,参数为一条数据对象
const dbRequest = dbStore.put({
id: 1,
name: '李四',
age: 22,
email: 'lisi@example.com'
});
dbRequest.onsuccess = e => {
console.log('数据更新成功~');
};
dbRequest.onerror = e => {
console.log('数据更新失败~');
};
5. 索引
在上面查询数据的例子中,使用了主键作为查询的目标,但在实际应用中,有很多情况下并不清楚主键的值,而是知道一个大概的值或者一个范围,此时便可以使用索引。
索引的意义在于,可以让你搜索任意字段,也就是说从任意字段拿到数据记录。如果不建立索引,默认只能搜索主键(即从主键取值)。
使用createIndex()方法创建索引,在创建仓库时,使用仓库实例进行创建,示例如下:
const myDB = indexedDB.open('myDB', 5);
myDB.addEventListener('upgradeneeded', e => {
const dbResult = e.target.result;
// 创建一个"用户信息"仓库 UserInfo
const createdStore = dbResult.createObjectStore(
'UserInfo',
{
keyPath: 'id',
autoIncrement: false
}
);
// 创建索引,索引值为ageIndex,对应的键名(或称属性)为age
createdStore.createIndex(
'ageIndex',
'age',
{
unique: false
}
);
});
createIndex(indexName, pathKey, options)方法接收三个参数:
indexName: 要创建的索引名,该值唯一,不可重复
pathKey: 仓库里需要建立索引的目标键名(key),或者多个键名组成的数组
options: 是一个可选的配置参数对象,有unique和multiEntry两个值
unique: 用来指定索引值是否可以重复,为true代表不能相同,为false时代表可以相同
multiEntry: 当第二个参数keyPath为一个数组时,如果multiEntry是true,则会以数组中的每个元素建立一条索引,如果是false,则以整个数组为keyPath值,添加一条索引.
下面是一个使用索引的栗子 :
const myDB = indexedDB.open('myDB', 4);
myDB.addEventListener('success', e => {
const dbResult = e.target.result;
const dbTrans = dbResult.transaction('UserInfo');
const dbStore = dbTrans.objectStore('UserInfo');
const lowerBound = IDBKeyRange.lowerBound(20);
const indexStore = dbStore.index('ageIndex');
const dbRequest = indexStore.openCursor(lowerBound, 'next');
dbRequest.addEventListener('success', e => {
const dbCursor = e.target.result;
if (dbCursor) {
const { key, value } = dbCursor;
console.log('id:', key);
console.log('name:', value.name);
console.log('age:', value.age);
console.log('email:', value.email);
dbCursor.continue();
} else {
console.log('编辑完毕~');
}
})
});
4.4 小结
看到这里,不难发现,indexedDB对于存储数据来说已经非常强大了,可以当做一个简易的数据库来使用了。唯一的不足可能就是使用方法比较麻烦,不过不用担心,早有轮子被人造出来了:
5. File System Api
5.1 介绍
近年来,随着web标准及浏览器功能的逐步完善,web应用的普及得以迅猛展开,其功能强、体验好、升级和维护成本低等优点已越发明显,大有取代传统桌面应用的趋势。但是一直以来,与桌面应用相比,web应用都有一个明显的不足,那就是文件操作(即访问客户端本地文件系统)。为了解决这一缺陷或者说优化这块的功能,HTML5带来了新的特性 - File System API。它能够帮助我们访问私有的本地文件系统沙箱(sandbox),在这里我们可以读和写文件,创建和排列文件夹,从而有效的弥补桌面和web应用之间的鸿沟。
目前只有 Google Chrome 浏览器对 File System API 有相对完善的支持。
5.2 获取权限
相对于桌面应用,web应用无需安装,接入途径简单,所以为了客户端安全性,web应用在使用文件系统前,需要取得用户许可,即获取文件系统访问权限。 获取权限需要使用window.requetFileSystem全局方法:
window.requestFileSystem(type, size, successCallback, errorCallback)
requestFileSystem()方法接受4个参数,其中type表示文件的持久性,可选值有两个window.PERSISTENT和window.TEMPORARY; size表示文件的大小,单位是字节,如5*1024*1024表示5M;successCallback表示成功获取文件访问权限后的回调,参数是一个FileSystem对象,可以使用该对象对文件进行后续操作;errorCallback(可选)表示授权失败后的回调,参数是一个FileError对象
window.PERSISTENT: 值为1,持久性的,适合长期保存用户数据
window.TEMPORARY: 值为0,临时性的,适合web应用来缓存临时数据
下面是一个获取权限的栗子
window.requestFileSystem = window.requestFileSystem || window.webkitRequestFileSystem;
// 申请一个5M大小的临时文件空间
window.requestFileSystem(window.TEMPORARY, 5*1024*1024, successHandler, errorHandler);
function successHandler(fs){
console.log('Welcome to File System~');
// 后续其他操作
// ...
}
function errorHandler(fe){
let msg = 'error: ';
switch (fe.code) {
case FileError.ABORT_ERR:
msg += '文件的操作命令被取消,可能是由于调用了FileReader的abort()方法';
break;
case FileError.ENCODING_ERR:
msg += '文件数据不能准确的被表示为一个data URI';
break;
case FileError.SECURITY_ERR:
msg += '由于安全原因,文件不能被访问';
break;
case FileError.NOT_FOUND_ERR:
msg += '找不到文件';
break;
case FileError.NOT_READABLE_ERR:
msg += '文件无法被读取';
break;
case FileError.PATH_EXISTS_ERR:
msg += '文件或路径已存在';
break;
case FileError.TYPE_MISMATCH_ERR:
msg += '非法文件类型';
break;
default:
msg += '未知错误';
break;
};
console.log('An error occured,', msg);
}
当然,web页面打开时并不知道之前是否申请过文件空间,可以在申请前做下判断:
window.webkitStorageInfo.queryUsageAndQuota(window.PERSISTENT, (used, remaining) => {
// used表示已使用的空间大小
// remaining表示全部空间大小
if (remaining == '') {
console.log('尚未申请空间');
} else {
console.log(`空间使用量为:${used}/${remaining}`);
}
}, errorHandler);
5.3 创建目录/文件
在拿到 FileSystem 对象(即 successHandler 回调参数 fs)后,可以在fs的根目录下创建文件夹或者文件
- 目录
- 创建目录
getDiretory()方法用来读和创建目录,如果第二个参数create为false,则为读取目录,创建成功的回调参数dirEntry为一个DirectoryEntry对象
// 在根目录下创建名为 Docs 的文件夹
//
fs.root.getDirectory('Docs', {create: true}, dirEntry => {
alert(`创建了名为${dirEntry.name}的文件夹`);
}, errorHandler);
注意:getDirectory()方法创建文件夹只能一个一个创建,如果我们想创建多层目录,比如Docs/a/b/c, 可以用变通的方法:
function createPath(parentDir, dir) {
parentDir.getDirectory(dir[0], {create: true}, dirEntry => {
if (dir.length) {
createPath(dirEntry, dir.slice(1));
}
}, errorHandler);
};
createPath(fs.root, 'Docs/a/b/c'.split('/'));
- 遍历目录内部文件
在读取到文件夹后,如何遍历文件夹中的内容呢?首先使用 DirectoryEntry 对象的 createReader() 方法创建一个 DirectoryReader 对象,然后通过 DirectoryReader 对象的 readEntries() 方法遍历内部文件:
fs.root.getDirectory('Docs', {}, dirEntry => {
const dirReader = dirEntry.createReader();
dirReader.readEntries(entries => {
for(let i = 0; i < entries.length; i++) {
const entry = entries[i];
// 使用fullPath返回文件(夹)的完整路径
if (entry.isDirectory){
console.log('文件夹: ' + entry.fullPath);
} else if (entry.isFile){
console.log('文件: ' + entry.fullPath);
}
}
}, errorHandler);
}, errorHandler);
- 删除目录
要删除一个目录,DirectoryEntry对象提供了两种方法:
remove(): 删除目录时,目录必须为空,否则会删除失败,执行errorHandler回调
removeRecursively(): 无论目录是否为空,都直接删除
下面是两个栗子
// 使用remove()
fs.root.getDirectory('Docs', {}, dirEntry => {
dirEntry.remove(() => {
console.log('目录删除成功');
}, errorHandler);
}, errorHandler);
// 使用removeRecursively()
fs.root.getDirectory('Docs', {}, dirEntry => {
dirEntry.removeRecursively(() => {
console.log('目录删除成功');
}, errorHandler);
}, errorHandler);
2. 创建文件
- 创建
getFile()方法用来读和创建文件,第一个参数可以是绝对或者相对路径,但是必须是合法的。例如,没有父目录创建一个文件会得到一个错误。第二个参数是一个参数对象。在下面的例子中:create:true 表示如果文件不存则创建一个文件,如果存在则抛出错误(exclusive:true),否则如果create:false,只是读取文件并返回。
// 在根目录下创建或者获取名为 test.txt 的文件
fs.root.getFile('test.txt', {create: true, exclusive: true}, fileEntry => {
alert(`创建了名为${fileEntry.name}的文件`);
}, errorHandler);
- 写内容
使用 FileEntry 对象的 createWriter() 方法创建 fileWriter 对象:
fs.root.getFile('test.txt', {create: false}, fileEntry => {
fileEntry.createWriter(fileWriter => {
// seek()方法接受字节偏移(byte offset)这个参数,并且设置fileWriter下次写入的位置
// fileWriter.length表示文件当前内容的字节长度,如果是新文件,可以省略下面这一步
fileWriter.seek(fileWriter.length);
window.BlobBuilder = window.BlobBuilder || window.WebKitBlobBuilder;
const blob = new BlobBuilder();
blob.append('这是随便写入的一些内容~');
fileWriter.write(blob.getBlob('text/plain'));
}, errorHandler);
}, errorHandler);
- 读取内容
使用 FileEntry 对象的 file() 方法和 FileReader 对象:
fs.root.getFile('test.txt', {}, fileEntry => {
fileEntry.file(file => {
const reader = new FileReader();
reader.onloadend = e => {
console.log('文件内容为:', reader.result);
};
reader.readAsText(file);
}, errorHandler);
}, errorHandler);
- 删除
使用 FileEntry 对象的 remove() 方法
fs.root.getFile('test.txt', {create: false}, fileEntry => {
fileEntry.remove(() => {
console.log('文件删除成功');
}, errorHandler);
}, errorHandler);
3. 目录及文件操作
这里说的操作,主要指拷贝、移动和重命名,因为 FileEntry 和 DirectoryEntry 对象做这些操作的方法相同,故而放到一起讲
- 拷贝和移动
即 copyTo()和moveTo()方法,两个方法使用方式和接受参数完全相同
copyTo(parentDirEntry, newName, successCallback, errorCallback);
moveTo(parentDirEntry, newName, successCallback, errorCallback);
parentDirEntry: 目标目录,即想要拷贝或移动到的目录文件夹 newName: (可选)拷贝或移动到新目录后的新名字,相当于操作结束后重新命名 successCallback: (可选)成功回调 errorCallback: (可选)失败回调
下面是两个栗子 :
// copyTo()
fs.root.getFile('test.txt', {}, fileEntry => {
fs.root.getDirectory('Docs', {}, dirEntry => {
fileEntry.copyTo(dirEntry);
}, errorHandler);
}, errorHandler);
// moveTo()
fs.root.getFile('test.txt', {}, fileEntry => {
fs.root.getDirectory('Docs', {}, dirEntry => {
fileEntry.moveTo(dirEntry);
}, errorHandler);
}, errorHandler);
- 重命名
这里重命名也是使用的 moveTo() 方法,只是将自身从当前目录移到当前目录并重命名而已
fs.root.getFile('test.txt', {}, fileEntry => {
fileEntry.moveTo(fs.root, 'testNewName.txt');
}, errorHandler);
5.4 小结
File System Api 目前来说还算是比较新的技术,普及程度不高,一方面是技术和标准不够完善和统一,另一方面各大浏览器厂商对于这种新特性的支持程度也是参差不齐。只能期待后续有所改进吧~
四、总结
只算是在前人的基础上又做了一点总结,参考和引用的地方实在太多,就不一一列出了。
文章有点长,很多地方不够完善,如有错误,望请勘正。

