策略算法工程师之路-损失函数设计



目录
1.常见损失函数
1.1 平方损失函数
1.2 绝对值损失函数
1.3 Huber损失函数
1.4 Hinge损失函数
1.5 交叉熵损失函数
1.6 指数损失函数
2.不对称损失函数设计
3.面向容错的损失函数设计
4.评测指标不可导时的损失函数设计
5.没有“Groud Truth“的损失函数设计
6.度量学习(Metric Learning)损失函数设计
7.面向稀疏样本的损失函数设计
8.层次损失函数设计
9.序列识别问题损失函数设计
10.多目标损失函数
机器学习建模时,尤其是传统方法中我们能自由发挥的地方除了各种特征工程外也就是目标函数的设计。在各种装X时刻(面试、答辩等)能对损失函数的设计发表下自己的见解或所用的奇淫技巧,还是很抓人眼球的。也是体现算法工程师“业务sense”的重要抓手!
先思考一个问题。损失函数、代价函数和目标函数是一回事吗? 三者之间的关系大概是这样的。
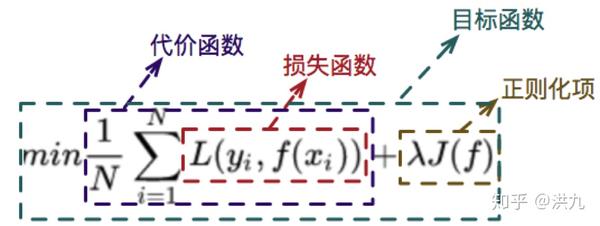

其中损失函数的设计要考虑符合问题所选定的ground truth,如果有多个ground truth,还需要做好trade-off。同时,损失函数要求有合理的梯度,可以被求解。
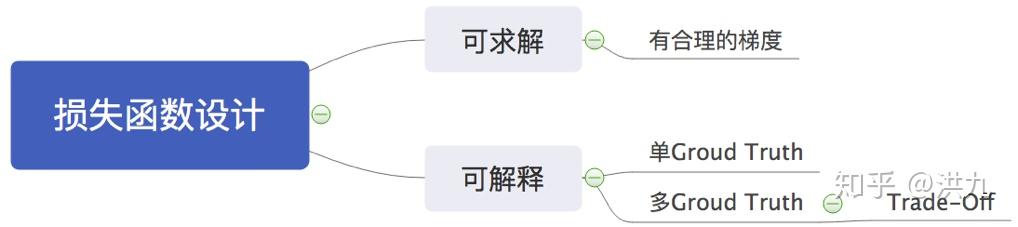

1.常见损失函数
损失函数是一个非负实数函数,用来量化模型预测和真实标签之间的差异。
1.1 平方损失函数

简单直观,易于求导,通常用于回归任务。但其背后也是有深刻的数学原理的。
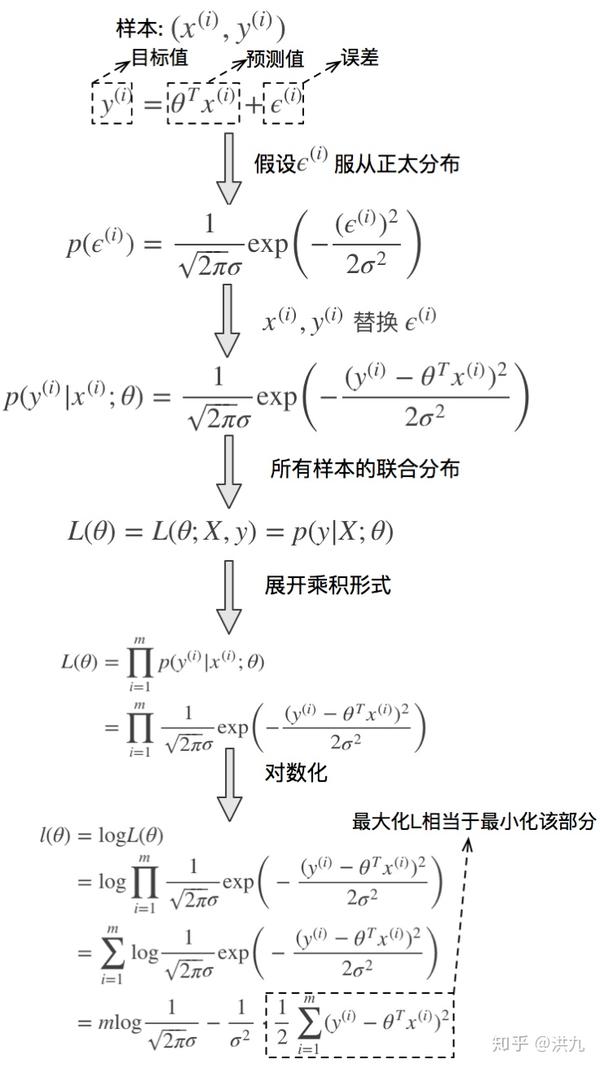

推导过程从最大似然出发,并且在误差服从正太分布的假设下,得出极大化最大似然等价于最小化残差平方和的结论。不过稍微了解下就可以了。
参考资料:
1.平方损失函数
2.平方损失函数为什么可以作为目标函数?
1.2 绝对值损失函数

这里只简单总结下MAE与MSE的区别:



更具体的可以参考:
1. L1 vs. L2 Loss function
2.机器学习大牛最常用的5个回归损失函数,你知道几个?
1.3 Huber损失函数
Huber Loss是一种用于回归问题的有参损失函数,其结合了MSE(处处可导)和MAE(对异常值不敏感)的优点。当预测偏差小于delta时,采用平方误差;当预测偏差大于delta时,采用线性误差。其中delta是需要确定的超参数。
Huber Loss定义如下:
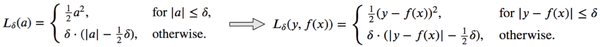

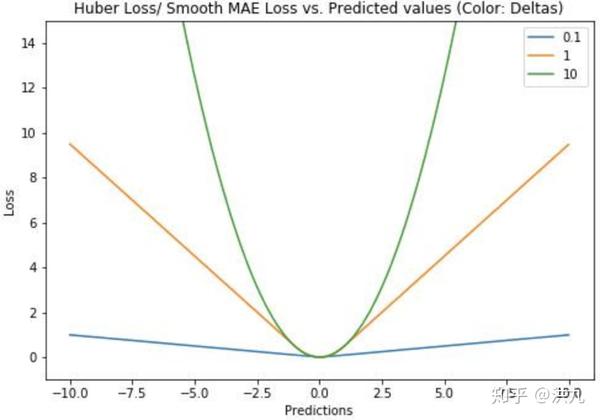

Huber Loss在实践中得到广泛了的应用。但是在要求损失函数二阶可导的情况下似乎有些问题,比如xgboost。此时可以用Psuedo-Huber Loss代替。


参考资料:
1. 回归损失函数:Huber Loss
https://blog.csdn.net/u013841196/article/details/89923475
2. Xgboost-How to use “mae” as objective function?
https://stackoverflow.com/questions/45006341/xgboost-how-to-use-mae-as-objective-function
3. 模型融合---Xgboost总结
https://blog.csdn.net/dili8870/article/details/101506486
1.4 Hinge损失函数


Hinge Loss通常用于分类问题,比如SVM。其中, Y 为目标值(-1或+1), f(x) 是分类器输出的预测值,并不直接是类标签。其含义为,当 Y 和 f(x) 的符号相同时(表示 f(x) 预测正确)并且| f(x) |≥1时,hinge loss为0;当 Y 和 f(x) 的符号相反时,hinge loss随着 f(x) 的增大线性增大。
再从 Hinge损失的观点看下SVM.
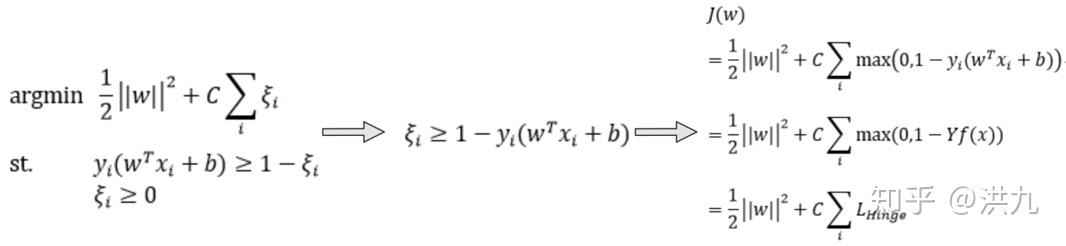

参考资料:
1.机器学习中常见的几种损失函数
https://www.cnblogs.com/hejunlin1992/p/8158933.html
2. Hinge loss
https://blog.csdn.net/hustqb/article/details/78347713
1.5 交叉熵损失函数
1.5.1 logistics loss
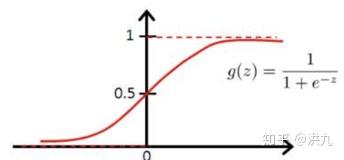
logistics loss通常用于逻辑回归分(类模型。
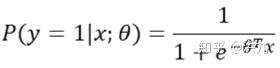


上述推导过程同样从极大似然出发得出二分类交叉熵损失形式。
更详细的推导:
https://blog.csdn.net/weixin_39910711/article/details/81607386
1.5.2 softmax loss
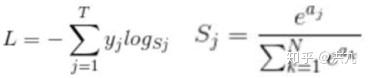
多分类问题时通常可以采用softmax loss。
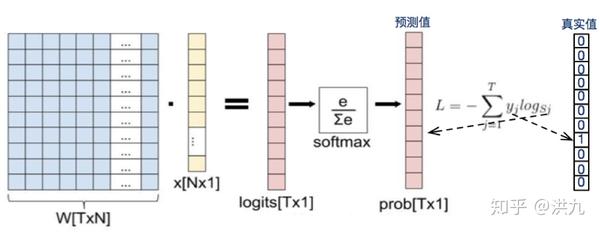

注意在softmax loss中,由于需要经过归一化操作,因此每个类别的预测不是相互独立的。为了加深理解我们可以看下softmax loss的梯度更新公式。


可以看出softmax loss在梯度传到时每个类别也不是相互独立的。“不相互独立“意味着每个样本只能属于一个类,而不能做多标签预测。如果想要做多标签预测可以参考下sigmoid cross entropy loss。
参考资料:
1.卷积神经网络系列之softmax loss对输入的求导推导
https://blog.csdn.net/u014380165/article/details/79632950
1.6 指数损失函数
敬请期待(没有时间写了).
// TODO
2.不对称损失函数设计
当基本的损失函数与业务场景不能很好匹配的时候,就需要做些微调。或许这是最能体现“算法工程师”功力的地方。考虑以下实际场景:
1).送达时间预估问题
XX业务中,展示给用户的ETA(预计送达时间)是一个基础变量,是用户下单决策的重要参考。显然要求ETA完全等价于“实际送达时长”是不可能的,除非开启上帝模式。因此用户感知上必然存在“迟到”和“早到”两种状态,其中“迟到”对用户体验的损伤更大一些,当然也偶有骑手送达而我们还在外面的情况发生。因此我们更希望模型的预估结果尽量“大”一些,尽量减少“迟到”的可能。很多时候用户需要的是“确定性”而非“有多快”。
2).疾病检测问题
在疾病监测领域中,一般认为假阴性比假阳性严重的多,因为错过最佳治疗时机的风险会更高。
上面2个例子告诉我们,在某些场景下要求模型对错误预测的惩罚是不对称的。本质上来源于风险的不对称性。此类问题的可以从样本分布、损失函数等多个角度优化,本小节重点说下如何从损失函数上优化。
在美团公开的资料中了解到在其ETA(预计送达时间)预估中采用如下形状的损失函数。
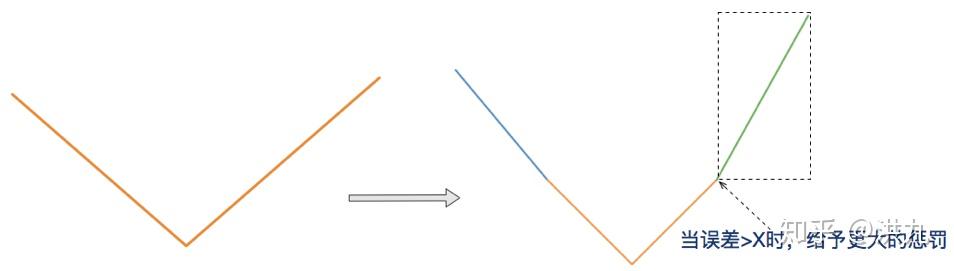

以LightGBM树模型为例,自定义Loss可能如下:


对模型预测结果做残差分析,可能如下图:


可以看出在采用非对称损失后残差分布相比与原有模型往右移动,也就是更偏高估了。
除了上述的方法外,还可以考虑Quantile Loss,即分位数损失。
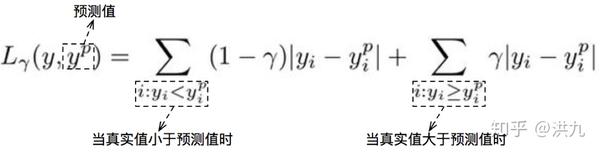

由上图可以看出,“真实值小于预测值”和“真实值大于预测值”两种情况下损失是不一样的。通过这种区分处理来决定模型是倾向于高估还是低估。
对,你是个“懂业务”的算法工程师。
3. 面向容错的损失函数设计
假设一个回归任务,可以容忍一定的误差。比如ground truth为7,则预测为[6,8]都是可以的,Loss可以设计如下:


本质上是L2 Loss和Hinge Loss的结合。
4.评测指标不可导时的损失函数设计


理想情况下,如果可以直接把评测指标作为损失函数结果肯定是最优的。但是很多情况下评测指标通常非凸且不可导,不容易直接优化。比如在搜索排序学习任务(LTR)中的NDCG指标。
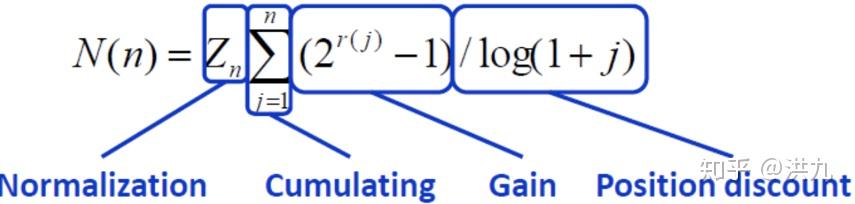



LTR(Learn to rank),其任务是寻找一个能够精确预测位置样本X的标号(序号)的决策函数,即排序学习所学习的预测函数将最小化对排序的预测错误。根据训练模型时输入数据的不同,曾经先后出现了Point-wise、Pair-wise、List-wise三种框架。
首先,Point-wise框架。

只考虑单个样本信息时,此时退化为点击率(CTR)预估问题。似乎也讲得通,CTR越高的样本越要排在前面。但是离我们的终极目标NDCG还是有Gap的。模型只学到了单个样本的信息,没有学习到样本间的“序”关系以及忽略了整个List内部信息。
其次,Pair-wise框架。
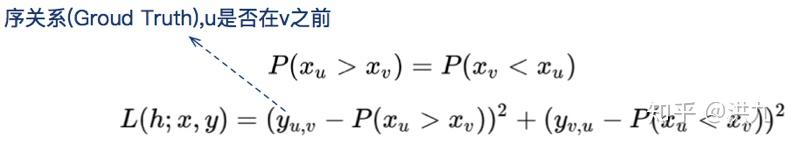

可见在Pair-wise框架下,损失函数考虑了“某一对样本u和v之间的序关系”。比上述Point-wise更接近我们的NDCG目标。可还是有问题的,如下图。
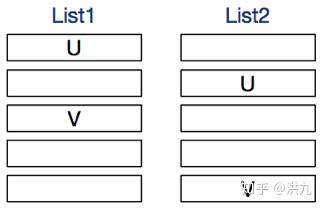
上图两个List中U都排在V之前,显然程度是不同的。因此Pair-wise的问题在于虽然考虑了Pair对的因素,而忽略了整个List的信息。
最后,List -wise框架。


好难啊! 相当于我们的输入是整个List,直接优化NDCG。但NDCG非凸且不可导,该怎么办呢? 参考下LambdaRank/LambdaMART的实现思路,既然无法定义一个符合要求的loss,那就直接定义一个符合我们要求的梯度。


上述推导过程就不必细看了,直接看最后的结果。
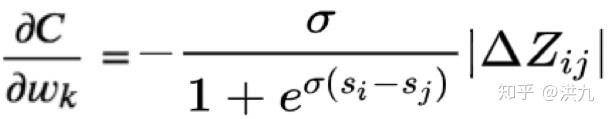

而我们可以根据业务需求自定义:
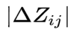
既然如此回到我们的优化目标NDCG,就可以定义:
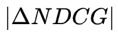
为对特定List,将Ui,Uj的位置调换,NDCG值的变化。所以我们就做到在NDCG非凸且不可导的情况下直接优化NDCG了。


参考文档:
1. 浅谈Learning to Rank中的RankNet和LambdaRank算法
https://zhuanlan.zhihu.com/p/68682607
2. 走马观花Google TF-Ranking的源代码
https://zhuanlan.zhihu.com/p/52447211
3. learning to rank 算法总结之pairwise
https://www.jianshu.com/p/235756fbf6b6
4. 学习排序 Learning to Rank:从 pointwise 和 pairwise 到 listwise,经典模型与优缺点
https://blog.csdn.net/lipengcn/article/details/80373744
5.没有"Groud Truth"的损失函数设计

没有Groud Truth,模型还可以Work?
Airbnb的研究人员在KDD 2018发表了一篇名为<<Customized Regression Model for Airbnb Dynamic Pricing>>的论文,描述了机器学习在动态定价中的应用。在Airbnb中,动态定价主要用于帮助房东指定最优价格。
何谓最优? 专业点说是使得供需平衡。通俗点说,可以包括以下两方面:
首先别太贵,否则租不出去。
其次别太便宜,否则让房东感觉亏了。
从上面可以看出,此问题最难的是如何确定Groud Truth(真值),什么样的定价是合适的? 暂且不管Groud Truth,先从建模角度了解下动态定价原理。Paper中介绍在最新的动态定价方案中将该问题直接建模为回归问题,即模型参考各种因素后直接输出推荐的价格。


考虑的因素主要如下:
页面因素,例如每晚的价格、房间类型、可住人数、房间数量、洗手间数量、房间设施、地理位置、评价、历史入住率、能否立即预定等等。
时间因素,例如季节、日期、可入住时间等等。
供给因素,例如周围是否有相似房源、评价、搜索率等等。
接下来还是要回到绕不开的Groud Truth问题。这里有两个假设。
首先,假设某一房源在历史上曾经以标价Pi租出去,说明在当时各种因素(房间、时间、供给等)下看来标价Pi是一个比较实惠的价格。这时房东有点心有不甘,倘若提高当时的价格到C2*Pi(C2是大于1的常数),也是有可能租出去的,因此此时的合理价格区间应该是[Pi,C2*Pi]。
其次,假设某一房源在历史上曾经以标记Pi没有租出去,说明在当时各种因素(房间、时间、供给等)下来看Pi是一个有些昂贵的价格。这时房东有点后悔,倘若降低当时的价格到C1*Pi(C1是0到1之间的常数),可能就租出去了,因此此时的合理价格区间应该是[C1*Pi,Pi]。


综上,此时的Groud Truth不再是一个点,而变成了一个合理区间[C1*Pi, C2*Pi]。到这,就可以写出损失函数了。
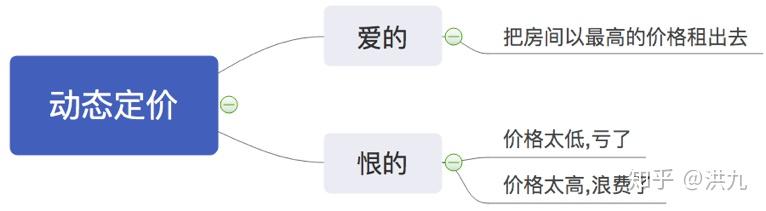



给定参数xi,fθ(xi)是输出的建议价格,L是下限函数,U是上限函数。
当建议价格在合理区间时,损失是零,否则损失就是建议价格和界限之间的距离。
参考资料:
1. Airbnb使用的动态定价模型
6. 度量学习(Metric Learning)损失函数设计
为什么需要度量学习? 最早接触度量学习是源于研究生时代的课题”基于人脸的血缘关系识别”。与人脸识别不同,血缘关系识别要回答的问题是“输入的两个人脸图像判断是否有血缘关系“。比如输入成龙和房祖名的人脸图像,期望得到的结果是“有血缘关系”。强势介绍下导师也是该领域的专家,周修庄老师。
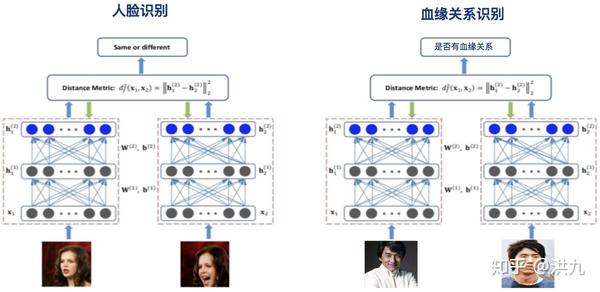

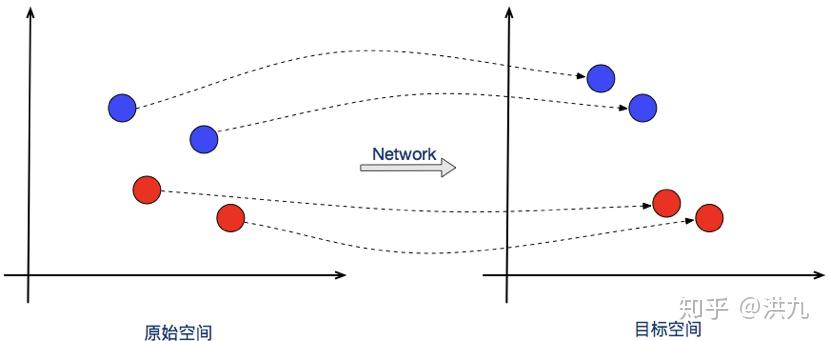
传统的分类任务(比如MINIST和ImageNet等),有一个很强但也很隐蔽的先验,即测试集中的类别一定在训练集类别中,此时模型已经学到了不同类之间的分界面。然而在人脸识别任务中此先验不再成立。假设全世界70亿人,对于人脸识别就相当于有70亿个类,而通常的人脸识别数据集也就1w左右的样本。所以需要改造传统的Loss,除了保证可分性外,还要做到特征向量类内尽可能紧凑类间尽可能分离。相当于引导分类器可以学习到能区分不同类的特征组合。
6.1 Contrastive Loss
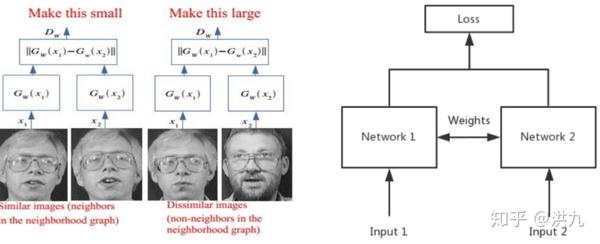

常用于深度度量学习。从拓扑的观点来看,Contrastive Loss使得网络学习到一种映射关系(神经网络或转换矩阵),把向量从原始空间映射到新的空间从而使得向量在新的空间有更好的拓扑性质,即类内尽可能紧凑类间尽可能分离。



当两个样本标签相同,即相似y=1,则欧式距离越大损失函数越大,反之,欧式距离越小,损失函数越小;当两样本不相似时y=0,只有后一项,若欧式距离越小反而loss越大;欧式距离越大loss越小。
代码参考:https://blog.csdn.net/u013841196/article/details/89875889
参考资料:
1. Siamese network 孪生神经网络--一个简单神奇的结构
https://zhuanlan.zhihu.com/p/35040994
2. 商品分类(一):Contrastive Loss + Softmax Loss
https://www.jianshu.com/p/713ab3a9ce9e
3. Contrastive Loss
https://blog.csdn.net/u013841196/article/details/89875889
4. Contrastive Loss(对比损失)
https://www.jianshu.com/p/21be99fb58ca
6.2 Center Loss
在最大化类间距离的同时,最小化类内距离。
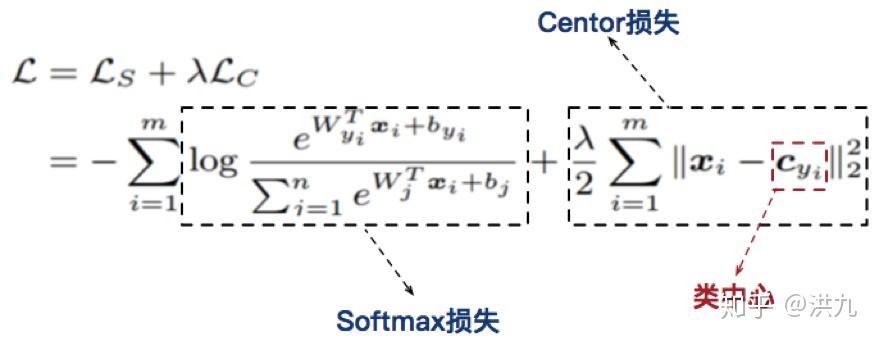



上图可以看出,随着lambda的增大类间的边界越来越清晰。
6.3 Triplet Loss
不多说了,都在图里。经常用在人脸识别任务中。


参考资料:
1. 深度学习干货学习(2)—— triplet loss
https://blog.csdn.net/zhuiqiuk/article/details/90640126
2. 详解Triplet loss三元组损失
https://blog.csdn.net/S20144144/article/details/102911057
6.4 LMCL Loss
敬请期待(没有时间写了)。
7.面向稀疏样本的损失函数设计
曾听别人说过,"做让自己难受的事情,是进步最快的捷径"。
上学那会,经常会发现有些看上去非常勤奋的同学成绩总是不尽人意。仔细观察就会发现,这些同学总是首先选择做那些自己得心应手的题目,而那些不会的题目则留在后面做甚至不做。所以看上去非常努力,实际上大部分时间在做无用功。
类似的问题同样存在于机器学习中。比如在计算机视觉目标检测任务中,通常存在着极度不平衡的样本比例问题。Anchor是一种类似sliding windows的选框方式(如下图)。在通过Anchor方法采样时,往往会使得正负样本的比例接近1:1000。并且这些负样本都是easy example,类比于那些容易做的题目。在优化过程中,梯度更新方向会被这些easy example过度影响。这些easy example的loss虽然不高,但由于数量众多最终会对loss有很大贡献,导致模型过度关注这些简单样本而忽略了占比比较小的困难样本。最终使得模型收敛到一个不好的结果。


发表于2017年ICCV的<<Focal Loss for Dense Object Detection>>提出了“Focal loss“来缓解one-stage目标检测中比例严重失衡的问题。Focal loss是在交叉熵损失函数基础上进行的修改,首先回顾二分类交叉上损失:
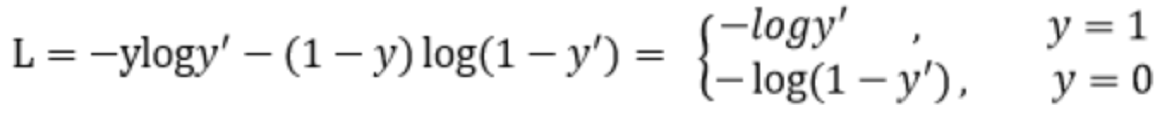

y^{'} 是经过激活函数的输出,所以在0-1之间。可见普通的交叉熵对于正样本而言,输出概率越大损失越小。对于负样本而言,输出概率越小则损失越小。该定义符合认知,在样本分布均衡时是没有问题的。但在样本分布极其不均衡时,损失函数在大量简单样本的迭代过程中比较缓慢且可能无法优化至最优。
那么Focal loss是怎么改进的呢?


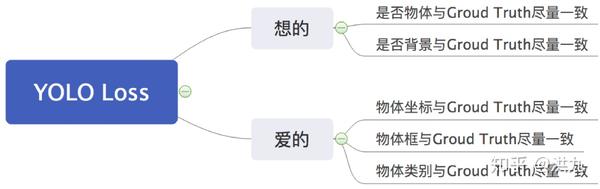
接着“把想的、要的挤进Loss“,如下:




首先在原有的基础上加了一个因子gamma。其中gamma>0使得减少易分类样本的损失,使得更关注于困难的、错分的样本。例如gamma为2,对于正类样本而言,预测结果为0.95肯定是简单样本,所以(1-0.95)的gamma次方就会很小,这时损失函数值就变得更小。而预测概率为0.3的样本其损失相对很大。对于负类样本而言同样,预测0.1的结果应当远比预测0.7的样本损失值要小得多。对于预测概率为0.5时,损失只减少了0.25倍,所以更加关注于这种难以区分的样本。这样减少了简单样本的影响,大量预测概率很小的样本叠加起来后的效应才可能比较有效。
综上,Focal Loss本质是通过各种调节因子对原始损失函数做修正。
参考资料:
1. Focal Loss for Dense Object Detection解读
https://www.jianshu.com/p/204d9ad9507f
8. Hierarchical Loss
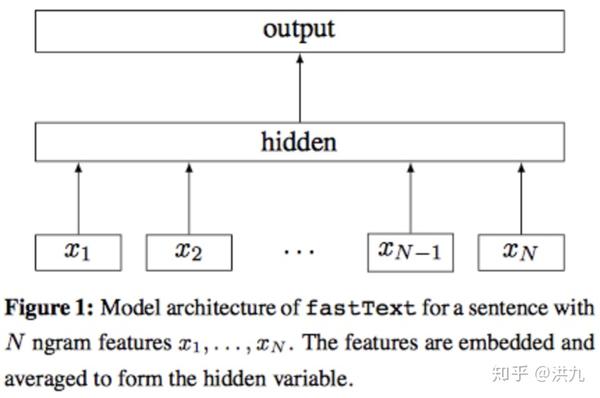

在短文本分类、意图识别等任务中,目前工业界常用的模型是Fasttext。Fasttext在结构上与word2vec有很多相似之处,毕竟出自同一人。首先,图模型结构很像,都是采用embedding向量的形式,得到 word的隐向量表达。其次,采用相似的优化方法,比如Hierarchical softmax。
为什么要采用Hierarchical softmax呢?先回顾下传统的分类任务中常用的softmax回归。


为了缓解这个问题,Fasttext引入了分层Softmax。
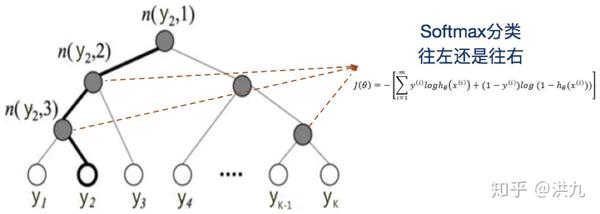
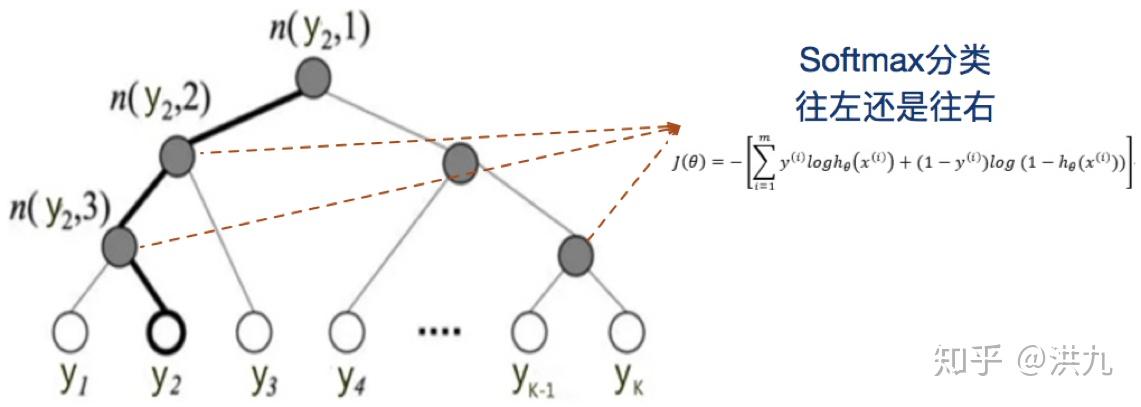
树的结构是根据类标的频数构造的霍夫曼树。K个不同的类标组成所有的叶子节点,K-1个内部节点作为内部参数,从根节点到某个叶子节点经过的节点和边形成一条路径,路径长度被表示为 L(y_{j}) 。于是, P(y_{j}) 就可以被写成:
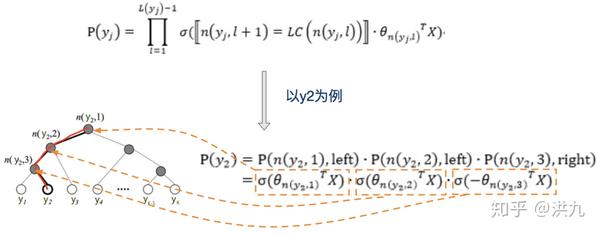

于是,从根节点走到叶子节点 y_{2} ,实际上是在做了3次二分类的逻辑回归。其中上图所示的树结构是根据类标的频数构造的霍夫曼树。假设我们现在用Fasttext模型做类目识别,还是用哈夫曼树构建树会存在什么问题呢? 很显然我们的类目树与哈夫曼树是不一致的,哈夫曼树在构建时仅仅考虑了频次,导致相邻节点之间并没有语义关系。既然发现了问题,解决思路也很简单了。
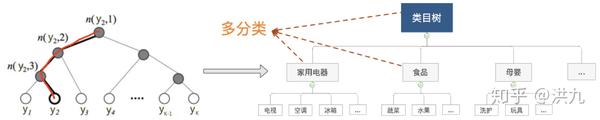

Fasttext也要做相应的扩展。
参考资料:
1.文本处理——fastText原理及实践
https://blog.csdn.net/u010417185/article/details/80649009
2. Hierarchical softmax(分层softmax)简单描述
Hierarchical softmax(分层softmax)简单描述.
3. Deep Metric Learning with Hierarchical Triplet Loss 阅读笔记
https://blog.csdn.net/gzw110605110/article/details/90186634
9.序列识别问题损失函数设计
CTC Loss常用于语音识别、手写字符识别等长度不确定的序列化建模场景。
先看下,确定长度的序列识别问题:


不确定长度的序列识别问题:


显然不确定长度的序列识别问题更困难一下。
一直觉得 CTC Loss是非常神奇的Loss,所以敬请期待(没有时间写了)。
参考资料:
1.CTC算法详解
https://www.jianshu.com/p/0cca89f64987
10. 多目标损失函数


子曾经曰过:“ 鱼,我所欲也;熊掌,亦我所欲也。二者不可得兼,舍鱼而取熊掌者也。”人生中很多问题需要我们做出抉择,比如工作与生活。我们既不能像偶像剧中的男女主人公一样天天琢磨怎么谈恋爱,也不能像某些同学一样周末还在写文章。因此我们需要对两者做出折中,也就是所谓的Trade-off。
言归正传,在实际的业务中,多目标相互“拉扯”的问题普遍存在。比如PV、GMV、用户体验等。通常在机器学习中解决多目标问题的思路大概有如下几种:
1.规则
单独训练ctr和cvr模型,线上排序时做经验加权。


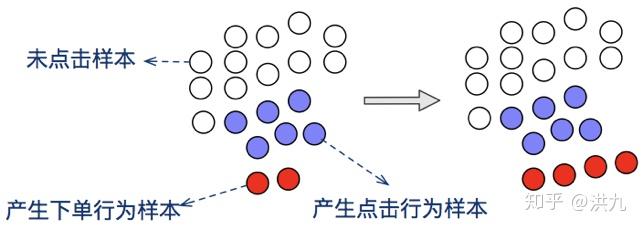
2.样本分布重构
考虑对有转化的样本重采样reweight。

3.多目标联合建模
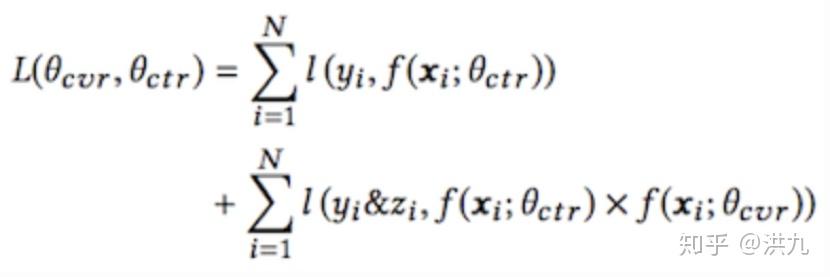

10.1 目标检测中的多目标


目前基于深度学习的Object Detection任务中,广泛采用end2end的方式,即目标位置、目标分类、目标框检测各子任务同时训练和预测而不再是传统的串联结构。在深度模型席卷计算机视觉领域以来,聪明的Cver设计出了很多end2end的深度目标检测模型。这里简单介绍下Redmond提出的YOLO(You only look once)模型。
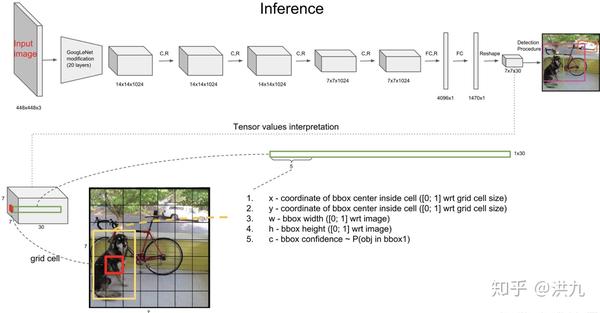

从上图看出,输入Image只要经过一次YOLO模型就可以Inference出每个目标的坐标、大小以及类型信息。YOLO的核心在于目标函数的设计。
先看下,YOLOv1的损失函数。
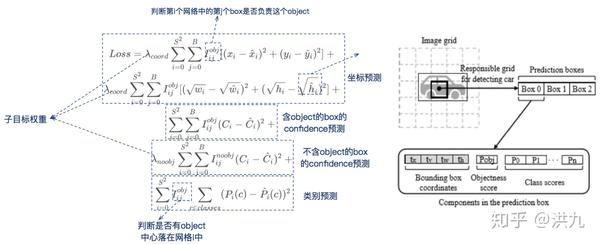

接着是YOLOv2的损失函数。


最后欣赏下YOLOv3的损失函数。


不难看出,YOLO损失函数设计的精髓是“把所有想要、爱的都挤在Loss!”。

10.2 电商CTR预估中的多任务
在电商搜索排序任务中,同时存在着ctr、cvr、gmv等多个优化目标。理想情况下,提升ctr就能提升gmv,但是实际情况可能会有偏差。单纯追求ctr的提升可能会导致“标题党”等吸引力较高但实际转化较低的商品占据头部流量,长此以往对用户体验和平台利益都有极大的损害。因此,实际线上搜索业务通常会同时优化ctr和cvr等指标。如下:
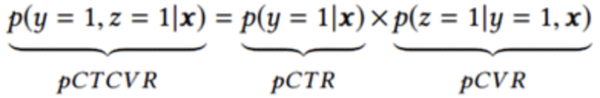

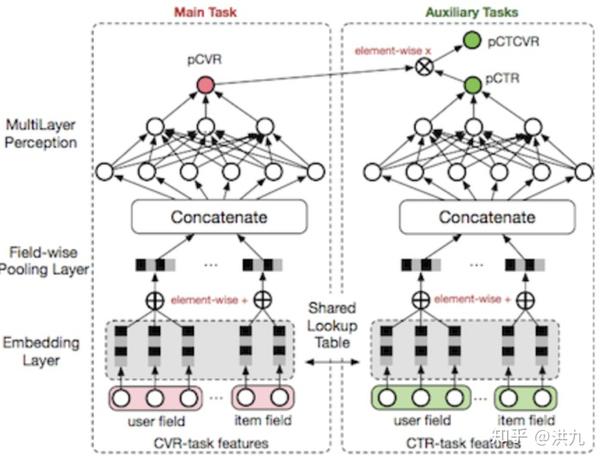
阿里在2018提出的ESMM(Entire Space Multi-Task Model)模型中同时考虑了ctr和cvr,本质是多目标学习。loss函数如下:
网络架构如下:

同时在信息流短视频推荐中也面临“感知相关性(CTR/CLICK)”和“真实相关性(停留时长RDTM/播放完成率PCR)”直接的trade-off。UC同时采用了reweight和多任务建模的方法。
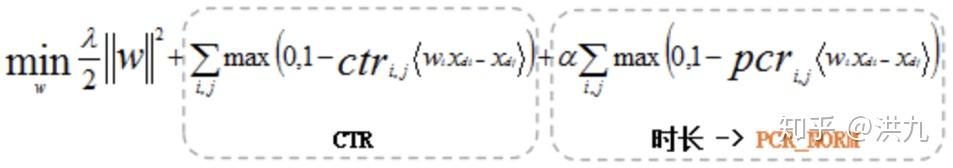

参考资料:
1.yolov3损失函数https://blog.csdn.net/weixin_43384257/article/details/100986249
2. 从yolov1到yolov3
http://shartoo.github.io/yolo-v123/
3. YOLOv1到YOLOv3的演变过程及每个算法详解
https://www.cnblogs.com/ywheunji/p/10761239.html
4. 深度学习在美团搜索广告排序的应用实践
https://tech.meituan.com/2018/06/07/searchads-dnn.html
5. 电商多目标优化小结
https://zhuanlan.zhihu.com/p/76413089
6. 推荐系统5---多目标排序
https://blog.csdn.net/weixin_40924580/article/details/85163372
7. 进击的下一代推荐系统:多目标学习如何让知乎用户互动率提升 100%?
https://www.jianshu.com/p/ed041f10f083
8. 信息流短视频时长多目标优化
https://yq.aliyun.com/articles/627734/
9. 深度多目标学习模型
10.为风控业务定制损失函数与评价函数(XGB/LGB)

